

こんにちは。MatrixFlow広報部の中野です!
今回はMatrixFlowを使ってワインに含まれる成分による品質分析をしたいと思います。
早速始めていきましょう!!!
データの用意
使うデータは、ポルトガルの「ヴィーニョヴェルデ」ワインの赤と白の成分(物理化学的性質)から品質をスコアで表しています。
以下のサイトからcsvデータをダウンロードします。
『Wine Quality Data Set』
https://archive.ics.uci.edu/ml/datasets/wine%20quality
ダウンロードしたファイルのデータ内容を見てみましょう!
1 – fixed acidity(酒石酸濃度)
2 – volatile acidity(酢酸濃度)
3 – citric acid(クエン酸濃度)
4 – residual sugar(残留糖分濃度)
5 – chlorides(塩化ナトリウム濃度)
6 – free sulfur dioxide(遊離亜硫酸濃度)
7 – total sulfur dioxide(総亜硫酸濃度)
8 – density(密度)
9 – pH(ph)
10 – sulphates(硫酸カリウム濃度)
11 – alcohol(アルコール度数)
12 – quality (score between 0 and 10)(品質(0から10の間のスコア))
※ブドウの種類、ワインのブランドなどに関するデータはありません。
今回は、品質(quality)のスコアの推論を実施するため、ダウンロードしたデータを一部別のファイルに移して「quality」の値を消去したファイルを作成しました。(推論用データ)
この段階で、用意したデータファイルは4つとなります。
①赤ワイン学習用データ
②赤ワイン推論用データ
③白ワイン学習用データ
④白ワイン推論用データ
このデータセットを使って、ワインの品質分析AIをつくっていきたいと思います。
では、MatrixFlowにアクセスして、“AI” で分析してみましょう!
MatrixFlowの操作
<プロジェクト作成>
MatrixFlowにログイン して、はじめに、プロジェクトを作成します。
プロジェクト一覧から「新規プロジェクトを作成する」をクリックします。

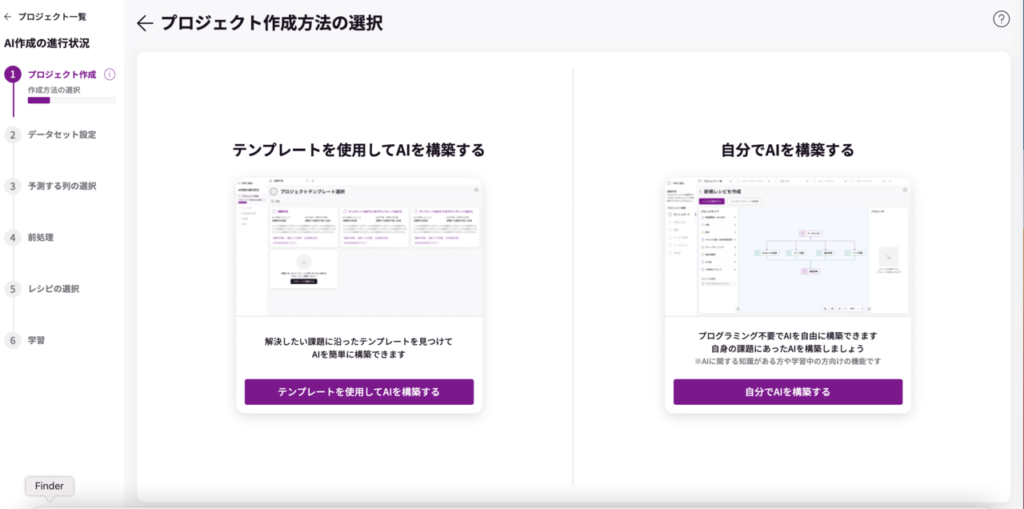
「テンプレートを使用してAIを構築する」または「自分でAIを構築する」のどちらかを選択します。今回は、「自分でAIを構築する」を選択します。
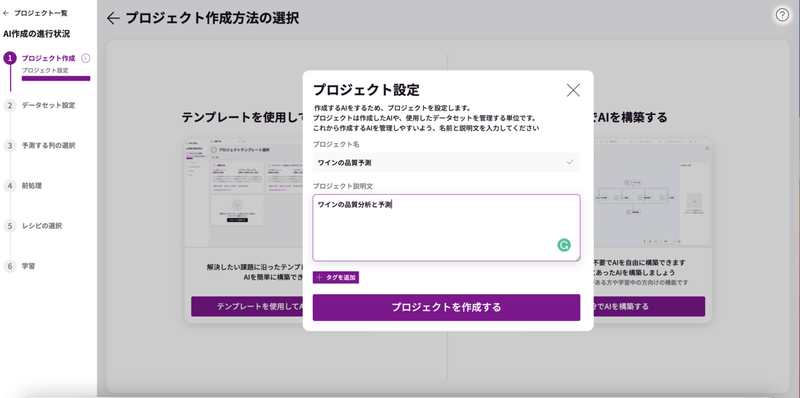
プロジェクト名とプロジェクトの説明を入れて作成します。

<データアップロード>
次に、データセットの設定を行います。使用するデータを設定するには、3つの方法がありますが、今回は「ファイルをアップロード」をします。
まずは、赤ワインから分析していきます。
上記で用意した「①赤ワイン学習用データ」の csvを所定の場所にドラッグ&ドロップします。
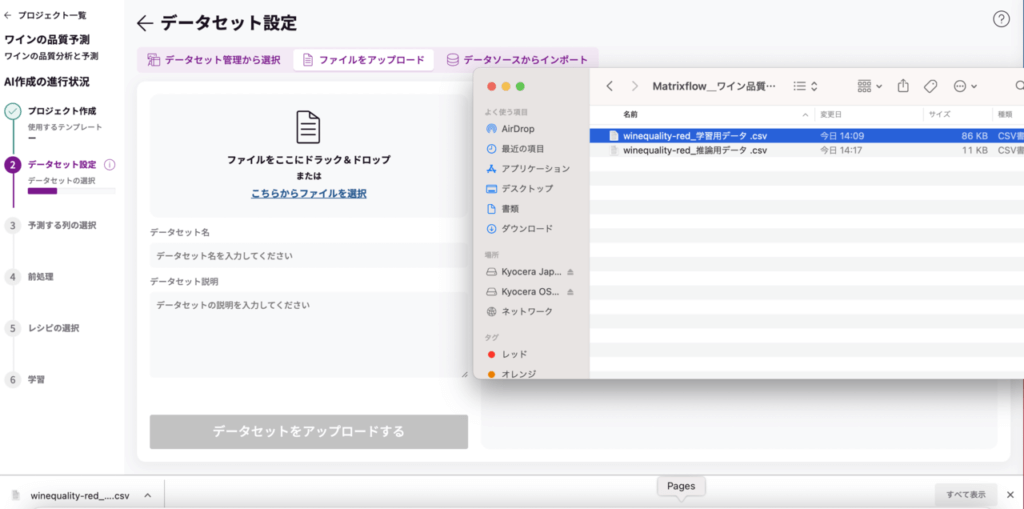
データを取り込めたようですね。ファイルの情報が表示されたら、名前と説明を入力して「データセットをアップロードする」をクリックしましょう。
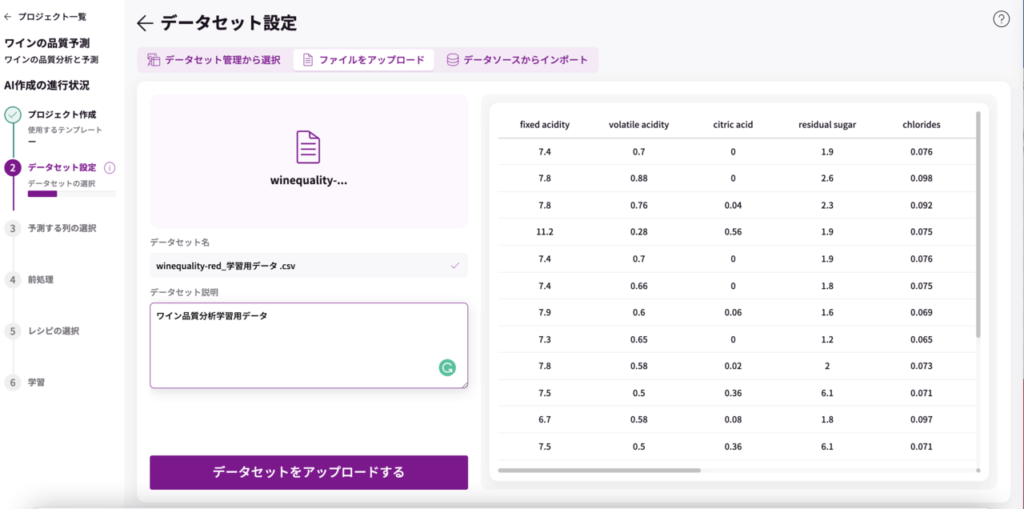
<予測する列の選択>
データセットをアップロードしたら、予測する列の選択画面に移行します。
ワインの品質を分析したいので、「quality」を選択し、「予測する列を決定する」をクリックします。
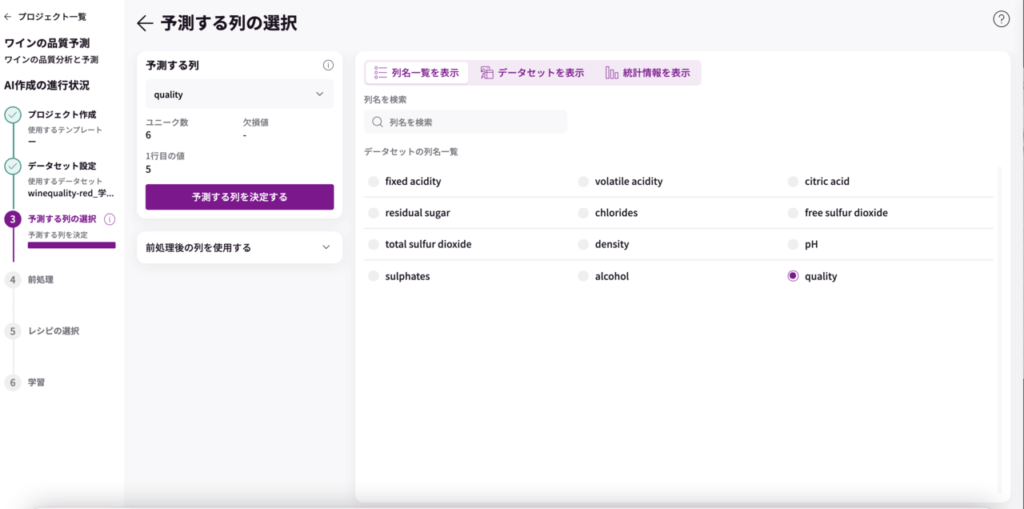
<データ前処理>
前処理のページへ飛びました。
ここでは、学習用データをAIが学習できる形に加工します。その工程を前処理と呼びます。
文字を数値変換したり、欠損値のある項目を特定の値で埋めたり、欠損値を含む行を削除します。
これを行うことで、AIの学習精度が上がります。
ここで、前処理を行う必要があると、エラー(赤字)表示されますが、今回はデータが整っていたので、前処理の必要はありませんでした。
何もせずに、左上の「前処理を完了する」をクリックします。
※前処理が必要な場合の方法については前回の記事で詳しく説明しています。
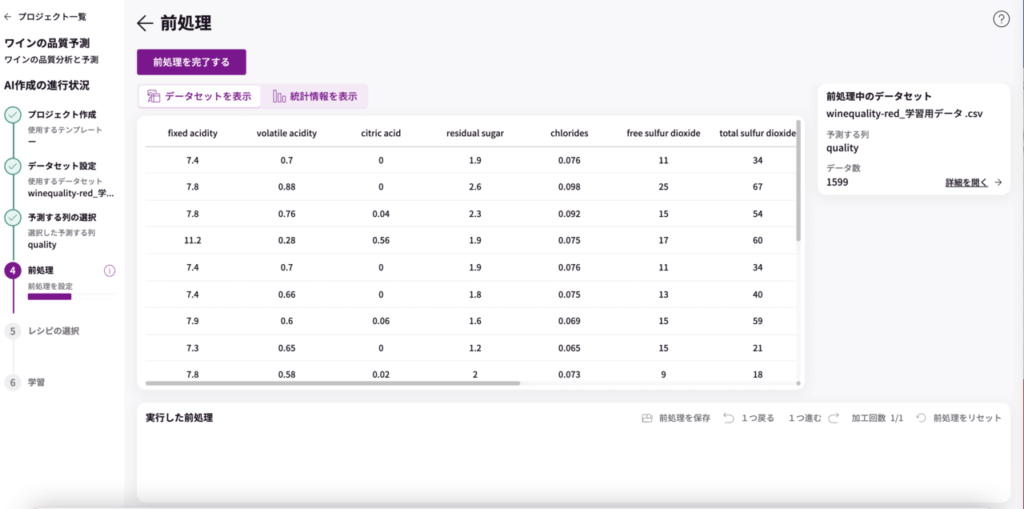
<レシピ>
データの準備ができたので、AIの設計図「レシピ」をつくっていきましょう!
レシピ管理のページで、新規作成ボタンをクリックします。
「ブロックタイプ」からAIで何をするのかを選びます。
今回は自動構築AIのAutoMLから「AutoFlow(オートフロー)」を使います。
※「AutoFlow(オートフロー)」自動で最も精度の良いアルゴリズムの選定とパラメータのチューニングを行います。
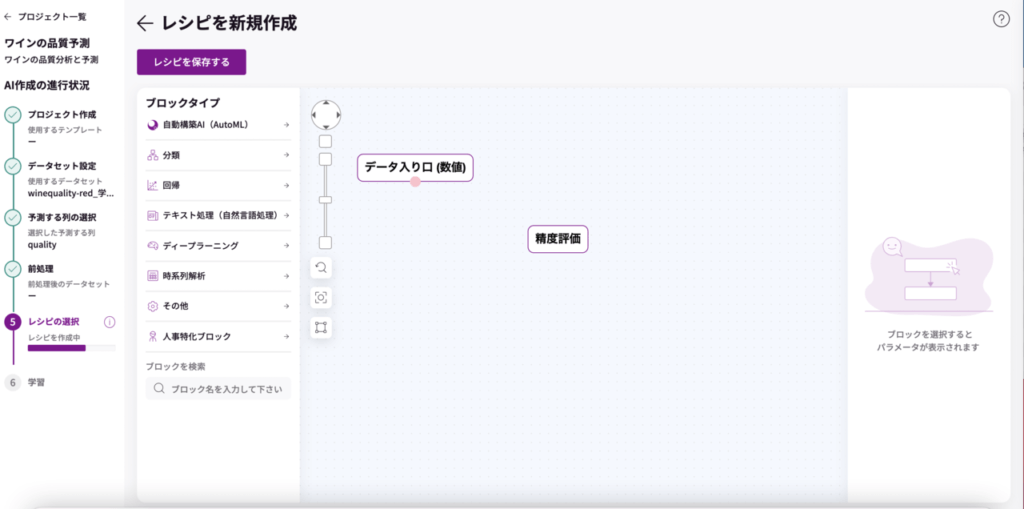
「AutoFlow」を設置エリアにドラッグアンドドロップして、「データ入り口」ブロックと「精度評価」ブロックに繋げます。
ブロックにポインターを合わせるとピンクの丸ポチが出てきますので、繋ぎたいブロックまで引っ張ります。
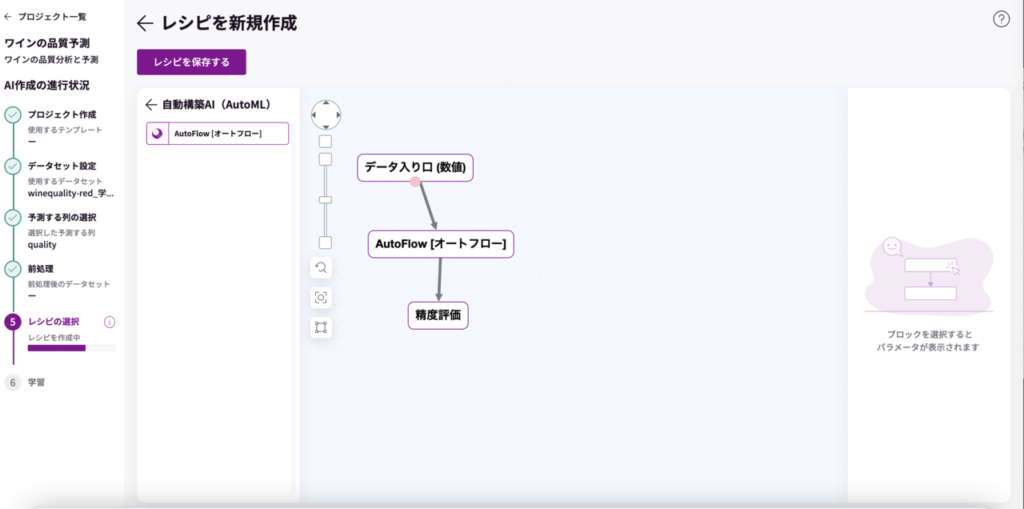
次に、AutoFlowのブロックをクリックすると、右側のパラメータが表示されます。種類の項目で「回帰」選択します。「レシピを保存する」をクリックし、「名前」と「説明」を入力して保存します。
※回帰分析は、複数データの関連性を明らかにする統計手法の一つです。ある成果の値変動に別の要素がどのくらい影響を与えているかを分析することができます。
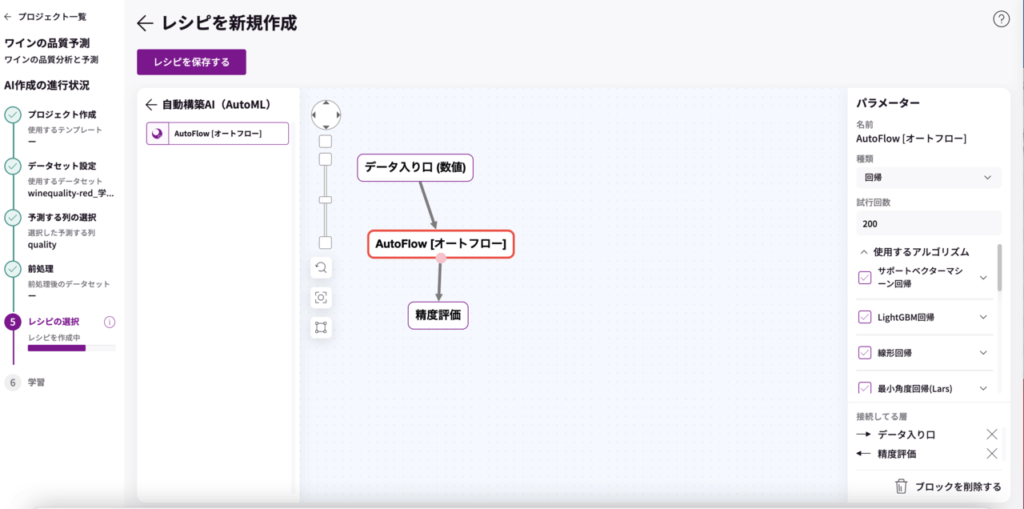
これでレシピの用意は完了です!
<AIの学習>
AIの学習ページで、学習に使用する列(項目)を選択します。
今回は、全て選択します。「列名」にチェックを入れると全て選択されます。
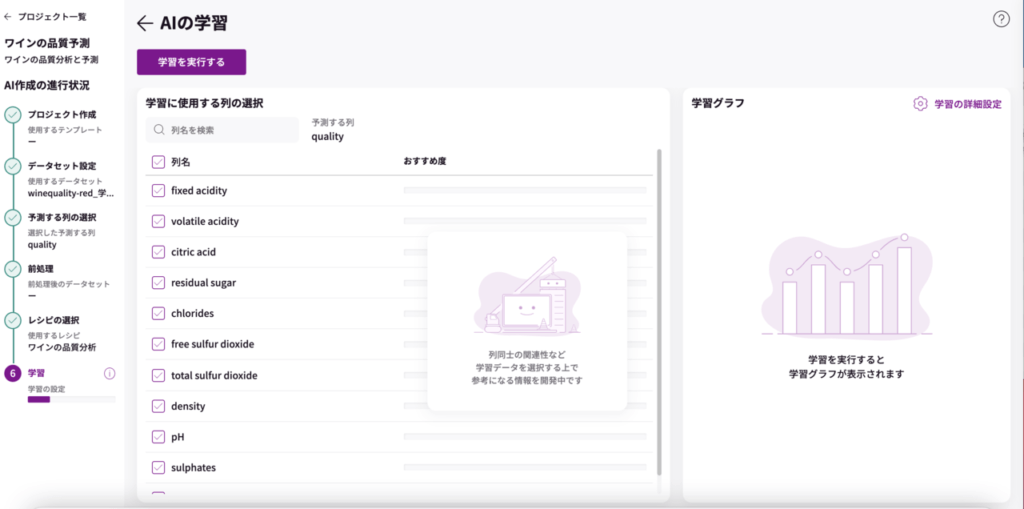
「学習を実行する」をクリックすると学習が始まります。
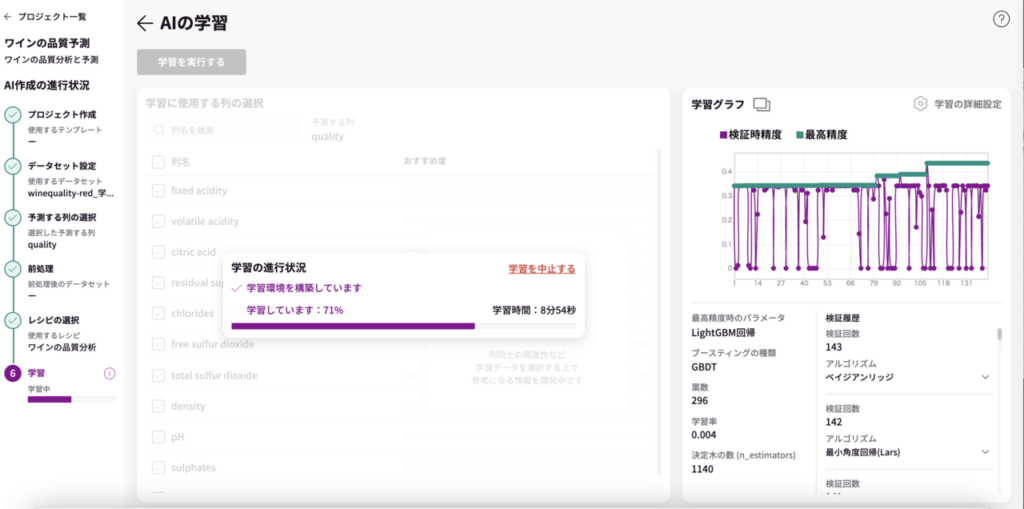
10分ほどで結果が表示されました。
分析結果は・・・?
品質においてアルコール成分がとても重要なんですね(fmfm)
続いて、硫酸カリウム濃度、酢酸濃度、総亜硫酸濃度、、、と続きます。
(ここでは結果は深掘りせず、分析の手順を最後まで説明しますね。
また、精度向上の方法に関しては続編の記事でご紹介します!)
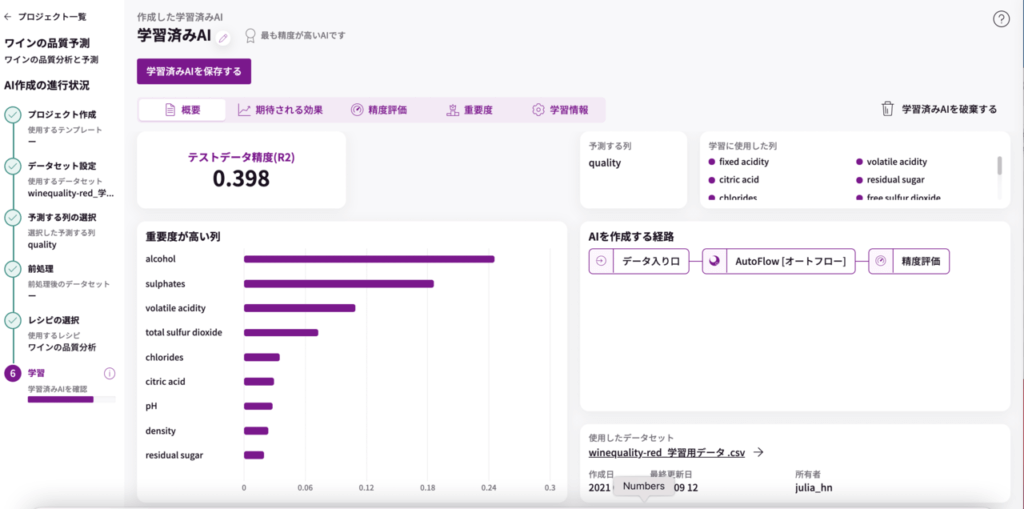
この学習結果を保存します。
左上の「学習済みAIを保存する」をクリックして「名前」と「説明」を入力し、保存します。
学習済みAIの保存が完了すると、「このAIを使って推論をする」または「引き続き学習する」の選択肢が出てきます。「このAIを使って推論をする」を選択します。
では、この学習データを元に、成分の値データから品質のスコアを予測してみましょう!
<推論>
推論の画面にとびますので、用意しておいた「②赤ワイン推論用データ(予測したいデータ)」をアップロードします。

すると、画面が切り替わりますので、「推論を実行する」をクリックします。

わずか数秒で推論結果が表示されました。(めちゃくちゃ早い!!^ ^)
「quality(品質スコア)」が入ってますね!
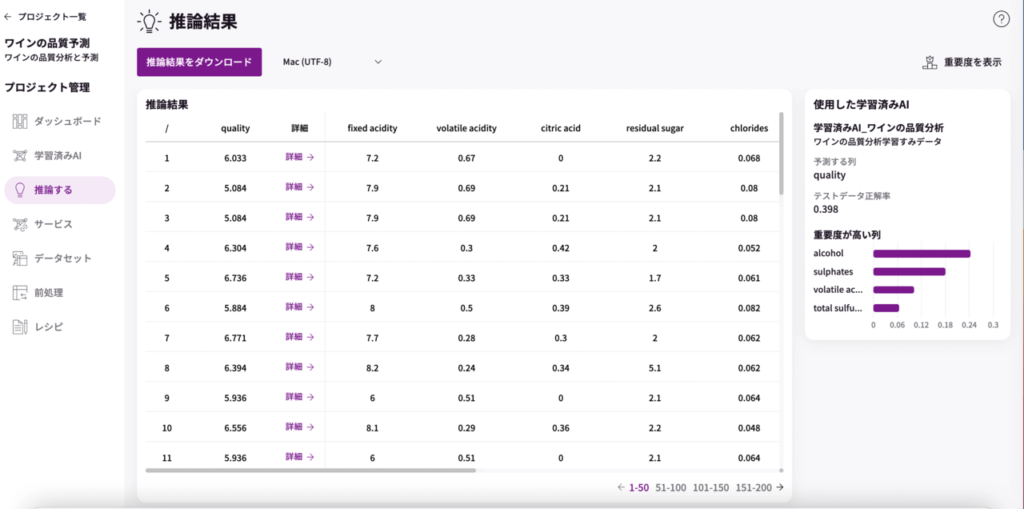
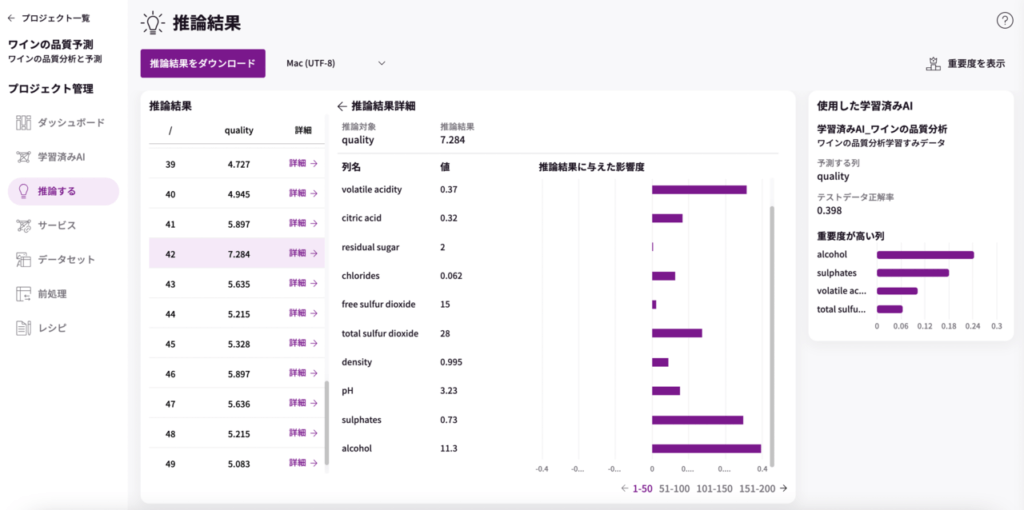
結果の一つの詳細を見てみましょう!中でもスコアの高いものを開いてみます。
推論結果に影響を与えた重要度が表示されています。右側に表示されている学習済みAIの重要度と合っていますね。

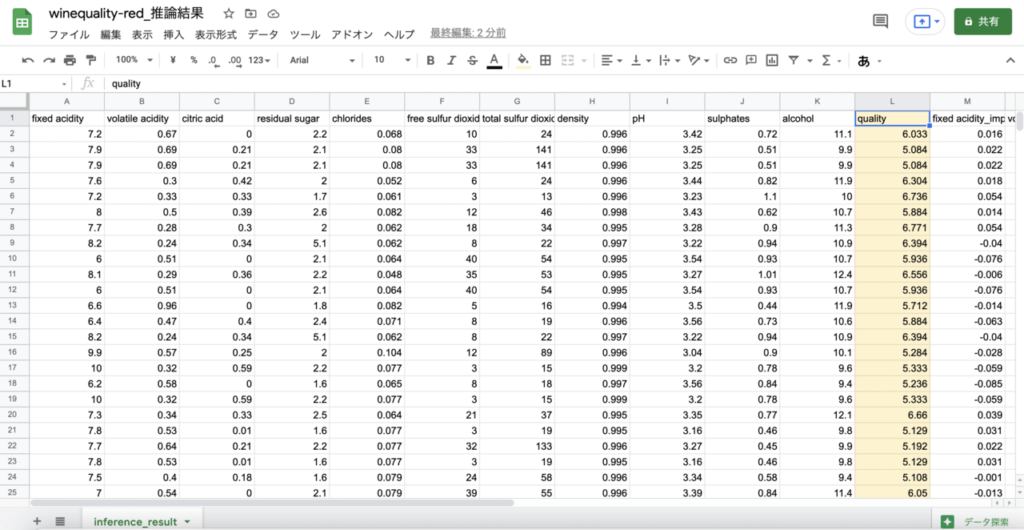
この結果は、左上の「推論結果をダウンロード」をクリックすると、csvファイルでダウンロードすることができます。
「quality(品質スコア)」はこのように表示されます。この結果は、左上の「推論結果をダウンロード」をクリックすると、csvファイルでダウンロードすることができます。
「quality(品質スコア)」はこのように表示されます。

右にスクロールすると、推論結果に影響を与えた重要度の値も見ることができます。
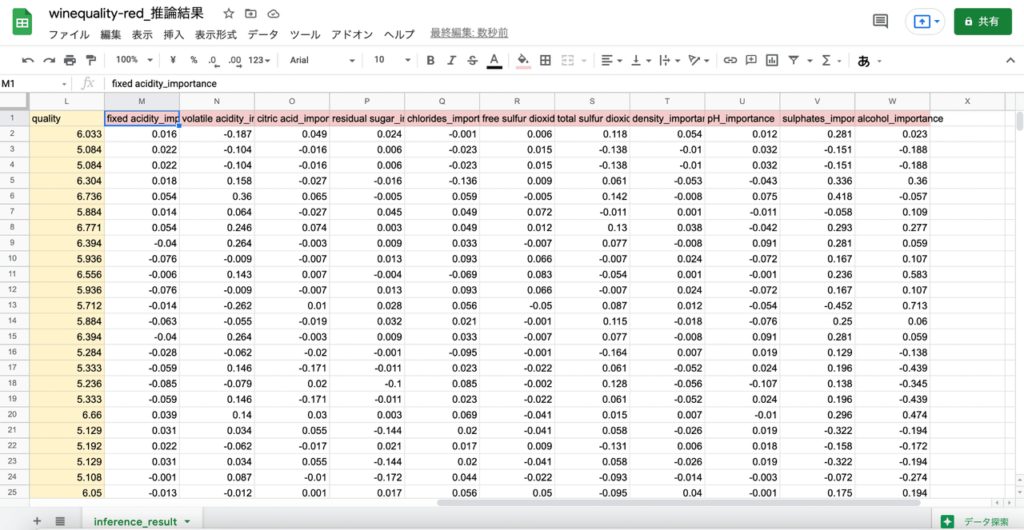
「quality(品質スコア)」の予測の流れはこのようになりますので、白ワインも同じように予測してみましょう!
<AIの学習結果を見てみる>
赤ワイン、白ワインの分析が完了しましたので結果をみてみましょう!
「quality」に対するそれぞれの重要度はどのようになっているのでしょうか?????
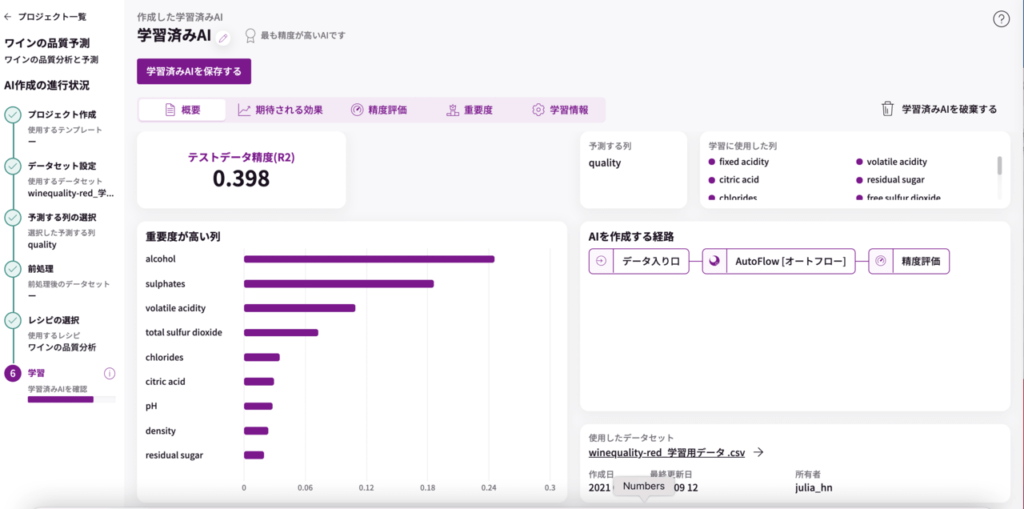
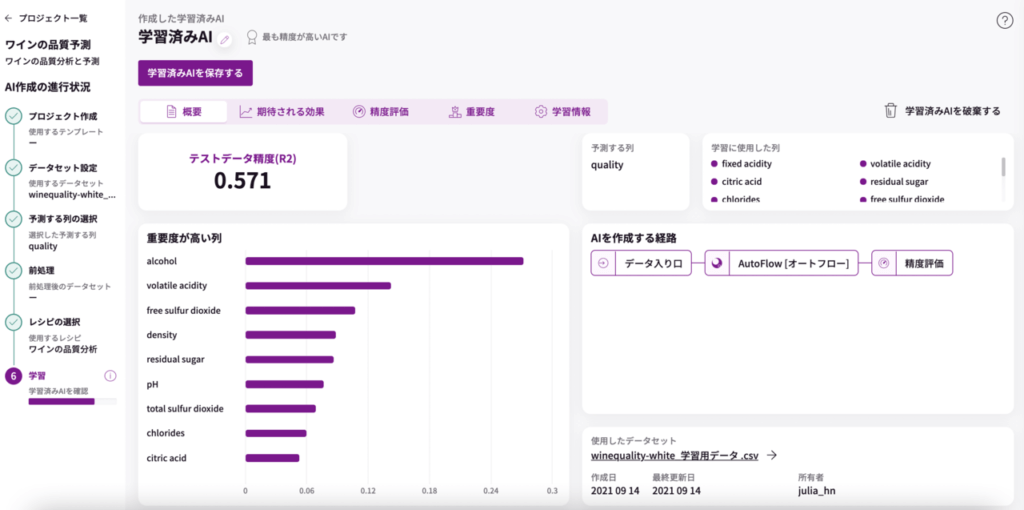
赤ワインも白ワインも「quality」を決める上で、『アルコール』が最も重要度が高いんですねー。
2つ目以降は全く違っていますね。
赤ワイン:
アルコール
sulphates(硫酸カリウム濃度)
volatile acidity(酢酸濃度)
total sulfur dioxide(総亜硫酸濃度)
chlorides(塩化ナトリウム濃度)
白ワイン:
アルコール
volatile acidity(酢酸濃度)
free sulfur dioxide(遊離亜硫酸濃度)
density(密度)
residual sugar(残留糖分濃度)
どちらも重要度の上位に入っている「volatile acidity(酢酸濃度)」ですが、酢酸濃度の存在が苦味、酸味のある余韻に起因しているようです。確かに、ワインを飲んだ時を考えると酢酸はワインに必要な存在といえそうですね。
亜硫酸には、酸化の防止、有害な微生物の殺菌や繁殖の防止、 など様々な効果があることから、その種類や濃度によって発酵の進み方が違ってくることで色や匂い、味などに影響するのではないでしょうか。
白ワインにある「residual sugar(残留糖分濃度)」は、果汁の香りを抽出するために、発酵温度を低めに設定することで発酵が止まりやすく、甘口のワインが生まれやすいとのこと。そのため、糖度の重要度が高くなるんですね。
赤ワイン学習結果(※上記画像と同じ)
白ワイン学習結果
このように、成分の量により赤 / 白 ワインの違いはもちろん、それぞれの中でも微妙な組み合わせの違いで品質が変わってくるんですね。
今回は用意したデータでそのままAIを作ってみました。
次回はより高い精度のAIを作成するための方法に関して、ご紹介します!
<まとめ>
このように、データがあればMatrixFrowでの操作は簡単です。
今回のように、品質の要因分析〜品質の予測というデータが出せれば、例えば、新商品の開発や販売価格の決定など幅広く使えるデータとなるのではないでしょうか。