Style-Bert-VITS2とは
Style-Bert-VITS2は、テキストから感情豊かな日本語音声を生成する高性能な音声合成モデルです。
このモデルは、BERTによるテキストの感情解析と、VITS2による音声生成技術を組み合わせており、入力テキストの内容や感情に応じた自然な音声を生成することができます。 GitHub
主な特徴
- 感情と発話スタイルの制御: 入力テキストの内容に基づき、感情や発話スタイルを強弱込みで自由に制御できます。これにより、喜び、悲しみ、怒りなど、多様な感情表現を音声に反映させることが可能です。
- ユーザーフレンドリーなインストール: GitやPythonの知識がなくても、Windowsユーザーであれば簡単にインストールして利用開始できます。また、Google Colabを利用した学習もサポートしており、GPUがない環境でも音声合成を行うことができます。
- Pythonライブラリとしての利用: 音声合成のみを行う場合、Pythonライブラリとしてインストールでき、他のアプリケーションとの連携も容易です。APIサーバーも同梱されており、外部システムからの利用もサポートしています。
- モデルの学習とカスタマイズ: ユーザー自身で新しい音声モデルの学習が可能で、オリジナルの声や特定の話者の声を再現することができます。学習データの準備やモデルのトレーニングも、提供されているツールやチュートリアルを活用することでスムーズに行えます。
このアルゴリズムを理解するためにまずはVITSについて調べました。
VITSとは
VITSについてもまとめておきます。
VITS(Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech)は、テキストから直接高品質な音声波形を生成するエンドツーエンドの音声合成モデルです。従来の音声合成システムは、テキストからメルスペクトログラムなどの中間表現を生成し、それを音声波形に変換する二段階のプロセスを採用していました。これに対し、VITSは単一のモデルで直接音声波形を生成することで、より自然な音声合成を実現しています。
VITSの主な特徴
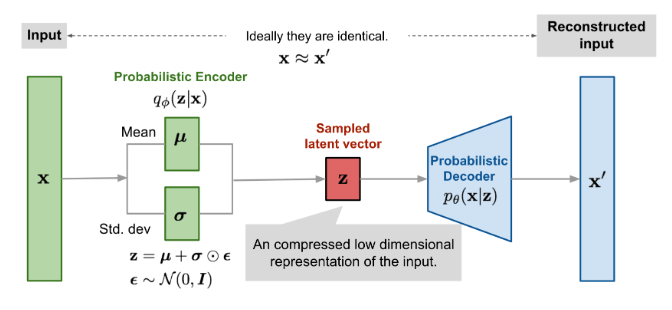
◾️変分オートエンコーダ(VAE)の採用
変分オートエンコーダを用いて、テキストと音声の間の潜在変数を学習します。
これにより、テキスト入力に対して多様な音声表現(例えば、異なるピッチやリズム)を生成する能力を持ちます。
https://www2.cs.arizona.edu/~pachecoj/courses/csc696h_fall22/lectures/vae_tuon.pdf
◾️正規化フローの利用
潜在変数の分布をより柔軟に表現するために、正規化フローを組み込み、生成モデルの表現力を向上させています。
正規化フローの基本的な考え方
- 潜在変数の分布をモデリング
- 通常の生成モデルでは、潜在変数zの分布として単純な正規分布(ガウス分布)を仮定することが一般的です。
- しかし、音声データのように複雑で非線形な構造を持つデータでは、この単純な仮定では表現力が不足し、生成された音声の品質が低下する可能性があります。
- フロー変換
- 正規化フローでは、単純な分布(例えば、正規分布)から複雑な分布を構築するために、一連の可逆変換(bijective transformations)を適用します。
- 各変換は微分可能で、変換前後の分布の確率密度を計算可能です。


◾️敵対的学習(GAN)の導入
生成された音声の品質を向上させるため、敵対的生成ネットワーク(GAN)を用いてモデルを訓練し、より自然な音声波形を生成します。
◾️確率的デュレーション予測器
入力テキストから多様なリズムの音声を生成するため、確率的デュレーション予測器を導入し、テキストと音声の一対多の関係を表現しています。 確率的デュレーション予測器は、各音素のデュレーションを単一の値ではなく確率分布として表現します。
デュレーションとは?
- デュレーションは、テキスト入力中の各音素(音声の基本単位)がどのくらいの長さで発声されるかを示します。
- 例: 日本語の「こんにちは」の場合、それぞれの音素(”こ”, “ん”, “に”, “ち”, “は”)に対応するデュレーションが異なります。
- 音声合成では、このデュレーションを正確に予測することが自然なリズムやイントネーションを生成するために非常に重要です。
確率的デュレーションの具体例
テキスト入力: 「こんにちは」
- 固定的なデュレーション:
- デュレーション: [0.2秒, 0.1秒, 0.2秒, 0.15秒, 0.25秒]
- 確率的デュレーション:
- デュレーション分布: ガウス分布(例: 各音素の平均値と分散を持つ)
- サンプリング結果: [0.18秒, 0.12秒, 0.22秒, 0.14秒, 0.26秒](バリエーションあり)
◾️推論プロセスの図
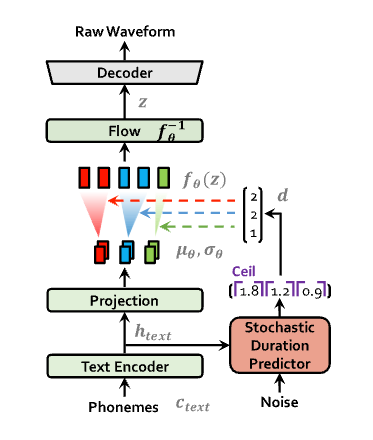
これらの技術により、VITSは従来の二段階モデルを上回る自然な音声合成を実現し、単一のモデルで効率的な学習と推論が可能となっています。さらに、VITSは外部のアライメント情報を必要とせず、モデル内部でテキストと音声のアライメントを学習することができます。
論文: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech

