このセクションの他の記事
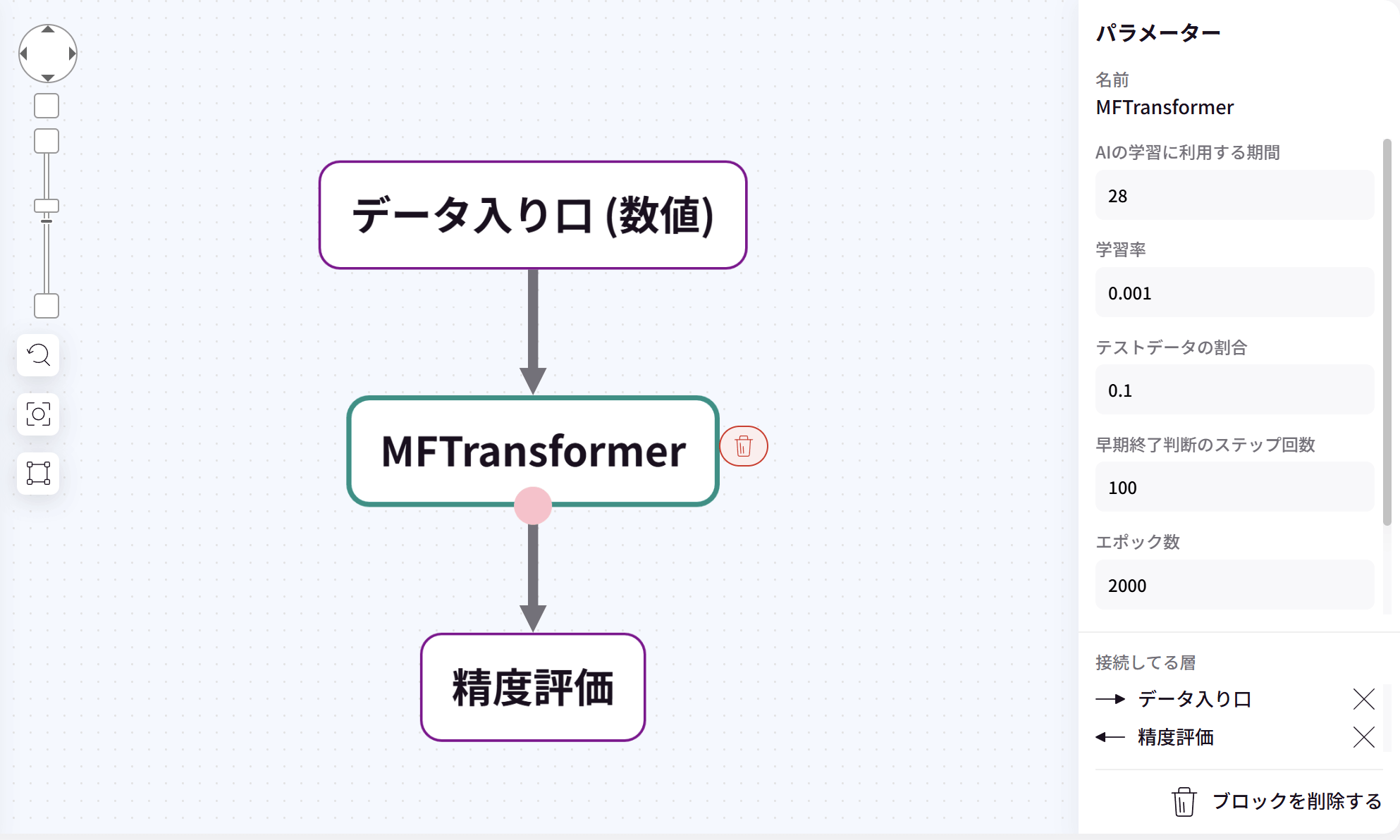
MFTransformerとは
MFTransformerは、未来を予測する時系列解析のレシピブロックです。
同じ時系列解析を行う TrendFlow と異なるのは、「学習に使用する列を複数指定できる」点と「予測は1行分のみ」である点です。
MFTransformerを使ったレシピは、プロジェクトテンプレート[平均雲量を日付のデータと気象状況から予測するAI]にセットされています。
■特徴
- 学習に使用する列(=説明変数)を複数列指定できる(TrendFlowは1列のみ)
- 投入したデータセットの最終行の次の1行分を予測
- あらゆるパターンの変化に対応して自動でフィット
■パラメータについて
[MFTransformer]ブロックは、レシピ編集画面のブロックタイプ「時系列解析」の中にあります。
データセットに合わせて次のパラメータを適切に設定します。
これ以外のパラメータの設定は、AIの知識をお持ちの上級者向けのため、納得感のある予測結果が得られるようであればデフォルトのままで差し支えありません。
1.入力列の長さ:28(デフォルト)
何行ずつ読み込んで学習を行うか、その行数を偶数で指定します。
偶数で指定しなかった場合、エラーにはなりませんが自動で偶数に丸められます。
※「テストデータの割合」との兼ね合いを考慮する必要があります。詳細は次項の<注意>をご覧ください。
<参考>学習は次の流れを繰り返して進みます。
① 指定した行数(=入力列の長さ)のデータを読み込む(例:2-29行目を読み込む)
② 次の1行を推論する(例:30行目を推論する)
③ 1行ずらし、指定した行数分のデータを読み込む(例:3-30行目を読み込む)
④ 次の1行を推論する(例:31行目を推論する)
⑤ (3)~(4)を繰り返し、最終行の推論が得たい予測値
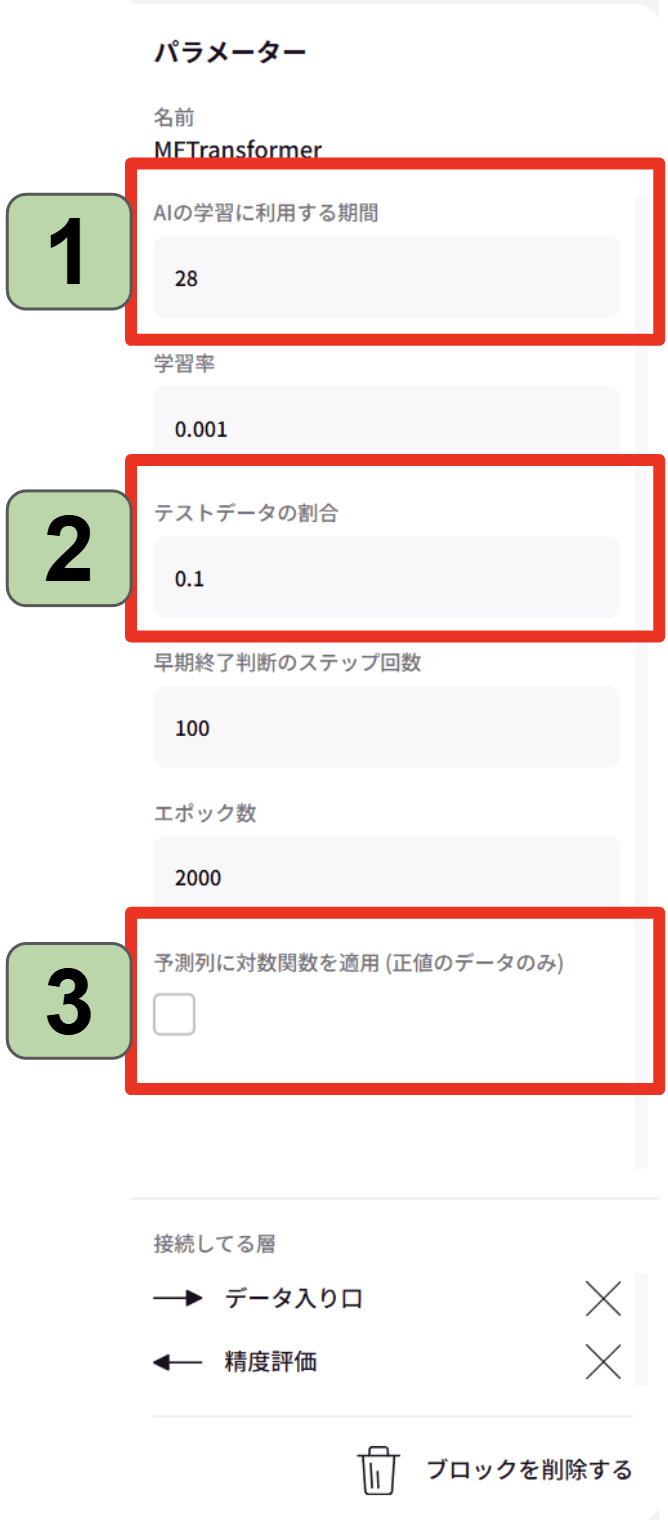
2.テストデータの割合:0.1(デフォルト)
学習データのどのくらいのデータ数をテストデータとして使うか割合を指定します。
デフォルトは0.1で、10%分をテストデータとして使います。
例)投入するデータセット=500行、テストデータの割合=0.1の場合、次のように分割されます。
・学習データ :450行
・テストデータ: 50行
<注意>ここに指定した割合により学習データからテストデータが分割されたとき、それぞれのデータ数が前項「入力列の長さ」に満たないとエラーになります。
例えば、投入するデータセットが200行で、入力列の長さを28、テストデータの割合を0.1と0.2に設定した場合、次の通りです。
| テストデータの割合 | 学習データ数 | テストデータ数 | OK / NG |
|---|---|---|---|
| 0.1 | 180 | 20 | NG (テストデータ数が入力列の長さ28に満たない) |
| 0.2 | 160 | 40 | OK |
3.予測列に対数関数を適用 (正値のデータのみ):OFF(デフォルト)/ON
この機能をONにすると、値を対数に変換して学習/予測を行います。
値の範囲が広かったり、外れ値を含んでいて予測結果が芳しくない場合などに利用すると、値の変化がなだらかになりピークが捉えやすくなるため有効なケースがあります。
結果は元に戻して表示します。
■データセットについて
冒頭で述べた通り、予測できるのは1行分です。
データセットの日付列が日次であれば最終行の翌日を予測し、週次であれば最終行の翌週を予測します。
日次のデータセットで1か月先の予測を行いたい場合は、日次データを合計したり、平均を取るなどして月次データに編集することで予測ができるようになります。