AutoMLを使って東京都心部のお値打ちマンションを見つけるAIを作成
目次
1.物件価格予測の問題設定
今回は、過去数年間の東京都内の分譲マンション販売実績価格を学習して、現在販売されているマンションの価格を予測し、お値打ちなマンションを探してみたいと思います。今回の試みのポイントは2つあります。
1つ目は学習に使うデータは「過去数年に渡って蓄積されたデータである」という点です。例えば、現在Web上で掲載されている販売中の物件だけを集めるのに比べて遥かに多数のデータを得られることが期待できます。一方で過去と現在では市況が全く異なっており、そもそも不動産価格自体が年代によって違うということが推測されます。すなわち「過去の不動産価格が安かった時代のデータ」ばかりを学習してしまうと、現在のマンション価格が過小評価される可能性があるのです。この点に注意を払う必要が出てきますが、上手く学習できれば現在の市況での価格をベースに、立地や広さなどから妥当な価格を予測できると期待できます。
2つ目のポイントは「販売実績価格を用いる」という点です。ここは非常に大きなポイントで、Web上で販売中のデータというのは実際にその価格で売れましたということを保証していません。裏で値引きが合ったり、あるいは売れ残っていて実質的価値と見合わない価格として残っているデータの可能性もあるからです。それに対し、過去の販売実績価格を用いると、現在販売中(=まだ販売価格が断定されていない)の物件の「実際に売れるとしたらいくらであるのか」を予測できます。
上記の考えに基づいて「AIが叩き出す販売予測価格>Web上で掲載されている提示価格」をお値打ちと定義し、お値打ちマンションを探していきたいと思います。
今回の学習に用いるデータは国土交通省土地総合情報システムからダウンロードしてきます。データの中身は後ほど紹介します。似たような試みとして、割安な賃貸物件を割り出すために一ヶ月の賃料を予測する問題を解いた例のリンクを貼ります。参考に後ほどご覧になってみてください。
機械学習を使って一番安い家賃の家に住む。〜前処理編〜 – Qiita
引っ越しすることになったので機械学習を使って全力で自分の住む家を決めようとした話 – Qiita
2.用いる特徴量
今回は賃貸ではなく分譲マンションの販売価格を予測するという問題をやっていきます。賃貸の予測と分譲マンションの販売価格の予測ではどのような違いがあるでしょうか。まず、賃貸の場合は物件の所有権は借り主にはないというのが大きな要素になります。なぜなら空調設備や壁紙、はてはリフォームの計画など、モノとしての管理は物件のオーナーが実施します。言い換えると、モノとしての状態に対して借り主には決定権が無いのです。置かれた状態なりの物件を借りるよりほか無く、結果的に空調設備や壁紙の見栄え等が、データとしては見えない形で賃貸料金に響いてきます。一方で、分譲マンションの価格はほとんど立地と建物で決まってくると考えられます。なぜなら、エアコン等の設備は通常備わっておらず、物件ごとの見えない差異にはならないことが多いのと、仮に細かな違いがあったとしても物件価格からすると誤差だと思ってしまっても差し支えない大きさだからです。すなわち、賃貸料金の予測に比べたら、構造化されたデータだけでもある程度は良い特徴量を集められ、予測を実施できると期待できます。
一方で、物件の売買においては「単に急に現金を要する事情ができた」とか「隣人がヤバい」などの理由で割安で物件を手放すということはありえます。賃貸価格というのは基本的に素性が分かりさえすれば比較的安定していることが多い一方で、販売価格は売り主の置かれた状況などで時系列方向に急激に値が変わったりすることはありうる(例えば借金を抱えてしまい差し押さえられた際の競売価格等を想像すればたやすい)ので、そういう点での難しさはあると考えられるでしょう。
国土交通省土地総合情報システム から落とせるデータには多くのカラムが存在します。まず「㎡(平方メートル)」などの機種依存文字などが使われていたり、面積のカラムに 78, 143 と数字が並んでいるはずが、突如 2000㎡以上 などのデータが混じっていたり、諸々おかしな表現が少数存在したため直しました(この記事を読んだ後にデータを触りたい人へのメッセージとして残しておきます)。
それらの表記上の問題を直した後、カラムから重要そうな特徴量を選定しました。また年数の表記が昭和や平成等の和暦が用いられていたため、それらは西暦にPythonコードで簡単な変換を施しています。(コード例は下記)
import pandas as pd
NAME_LIST = [
"minato-ku.csv",
"chiyoda-ku.csv",
"bunkyo-ku.csv",
"chuo-ku.csv",
"shinjuku-ku.csv",
"shibuya-ku.csv",
]
DATA_NAME_OUTPUT = "ALLDATA"
def read_csv(name):
return pd.read_csv(name, encoding="shift-jis")
def drop_columns(df):
mansion_idx = df["種類"] == "中古マンション等"
df_mansion = df[mansion_idx]
df_mansion = df_mansion.loc[df_mansion["建築年"].dropna().index, :]
df_mansion = df_mansion.loc[df_mansion["最寄駅:距離(分)"].dropna().index, :]
df_mansion = df_mansion.loc[df_mansion["面積(m^2)"].dropna().index, :]
df_mansion = df_mansion.loc[df_mansion["取引価格(総額)"].dropna().index, :]
df_mansion = df_mansion.drop(columns=["地域", "坪単価", "取引価格(m^2単価)", "間口", "延床面積(m^2)", "土地の形状", "前面道路:方位", "前面道路:種類", "前面道路:幅員(m)", "取引の事情等"])
return df_mansion
def add_columns(df):
def convert_hour(x):
if type(x) == float:
return x
if "H" in x:
return 60
else:
return float(x)
def convert_years(x):
heisei = 1988
showa = 1925
rewa = 2018
if "昭和" in x:
return int(x[2:-1]) + showa
if "平成" in x:
return int(x[2:-1]) + heisei
if "令和" in x:
return int(x[2:-1]) + rewa
def convert_transac(x):
return float(x[:4])
df["建築年(西暦)"] = df["建築年"].apply(convert_years)
df["築年数"] = 2022 - df["建築年(西暦)"]
df["最寄駅:距離(分)"] = df["最寄駅:距離(分)"].apply(convert_hour)
df["取引価格(総額)"] = df["取引価格(総額)"].apply(float)
df["面積(m^2)"] = df["面積(m^2)"].apply(float)
df["取引時点(西暦)"] = df["取引時点"].apply(convert_transac)
df["取引時点_築年数"] = df["取引時点(西暦)"] - df["建築年(西暦)"]
return df
def to_csv(df, name):
df.to_csv(name+"-preprocessed"+".csv", index=None)
def all_sequence(name):
df = read_csv(name)
df = drop_columns(df)
df = add_columns(df)
return df
def main():
df_list = [all_sequence(name) for name in NAME_LIST]
df = pd.concat(df_list, axis=0)
to_csv(df, DATA_NAME_OUTPUT)
if __name__ == "__main__":
main()
最終的に利用した特徴量は下記の通りです。
応答変数:取引価格
説明変数:地区名、最寄駅、駅徒歩、間取り、面積、建物構造、改装、建築年、取引時点の築年数
説明変数の例は以下のようなものが考えられます。
地区名:若宮町
最寄駅:飯田橋(離散値)
駅徒歩:9(連続値)
間取り:2LDK(離散値)
面積:55.31(連続値)
建築構造:RC(離散値)
改装:改装済(離散値)
建築年:2017(連続値)
取引時点築年数:5(連続値)
2017年に建てられたこの物件は、5年後に取引が成立していることになっています(今年ですね)。価格は7980万円でした。年代を遡ることで、このようなデータが各区で1万件以上獲得できます。各特徴量の意図を説明します。
まず連続値はそのまま活用するとして、例えば最寄り駅の名前や建築構造などの離散値はどのように扱えば良いでしょうか。前処理の方法や考え方は色々存在しますが、今回は離散値に関してはMatrixFlowの提供するラベルエンコーディングを用いました。(ワンホットエンコーディングやターゲットエンコーディング等、他にも方法はあり、MatrixFlowにはラベルエンコーディングとワンホットエンコーディングが準備されています)
地区名、最寄駅に関しては両方を入れる必要があるかは迷いましたが、最寄駅が同じでも別の地区であるケースも多々考えられるために特徴量としました。例えば駅の南側と北側で地区が異なり、物件価格にも響いているケースが考えられるでしょう。
次に間取りと面積は物件の非常に重要な要素と考えられるので文句無しに選定しています。実は元々の生データには他にも「面積あたりの価格」という特徴量がありました。これはある意味でその立地の価値を直接表記する重要な特徴量です。今回は物件の販売価格を予測したいため、仮に「面積あたりの価格」を説明変数に含めてしまうと、面積×面積あたりの価格で他の特徴量を見なくとも正解を計算できるという状況(リーク)となってしまうため、特徴量から省きました。また、実際にまだ販売が済んでいない物件の予測価格を出す段階では「面積あたりの価格」は手に入らないデータなので、無論、学習時に使って良いデータではありません(どこからか採取してきたデータはこのような入れてはならないカラムが多々存在するため注意が必要です)。
建築構造に関してはRCか木造かで、物件の耐用年数が大きく変わるため重要だと考えました。改装済であるか否かは、物件価格に対しては小さな変動かもしれませんが、改装してキレイに整えてから販売する(そして価格を釣り上げる)ことはよくある方針だと思われるため入れておきました。
建築年と取引時点築年数は今回最も注意が必要な特徴量です。まず、今回活用するデータは現在販売されている物件ではなく過去数年に渡って得られた販売実績です。したがって、「いつ建てられたのか」と「建てられてから何年後の取引なのか」の情報が両方効いていきます。例えば、販売された時点で「築10年」だったとしても、それが「2010年に建てられた物件の2020年時点での販売実績」なのか「1999年に建てられた2009年時点での販売実績」なのかで、価格が大きく異なることも予想されます。したがって、いつ建てられたのか、そしていつ取引されたのか(=取引成立時の築年数)の情報も同時に必要だと考えられます。もしも、いつ建てられたのかの情報がない場合は、時代による市況を反映できない事になるため、全時代の平均的な価格を出してしまう結果となるでしょう(ここ10年は物件価格は上昇し続けているので、現在の物件価格を予測する上では過小評価になってしまう)。今回用いるデータの販売実績の年代は2000年代半ばに集中しています。
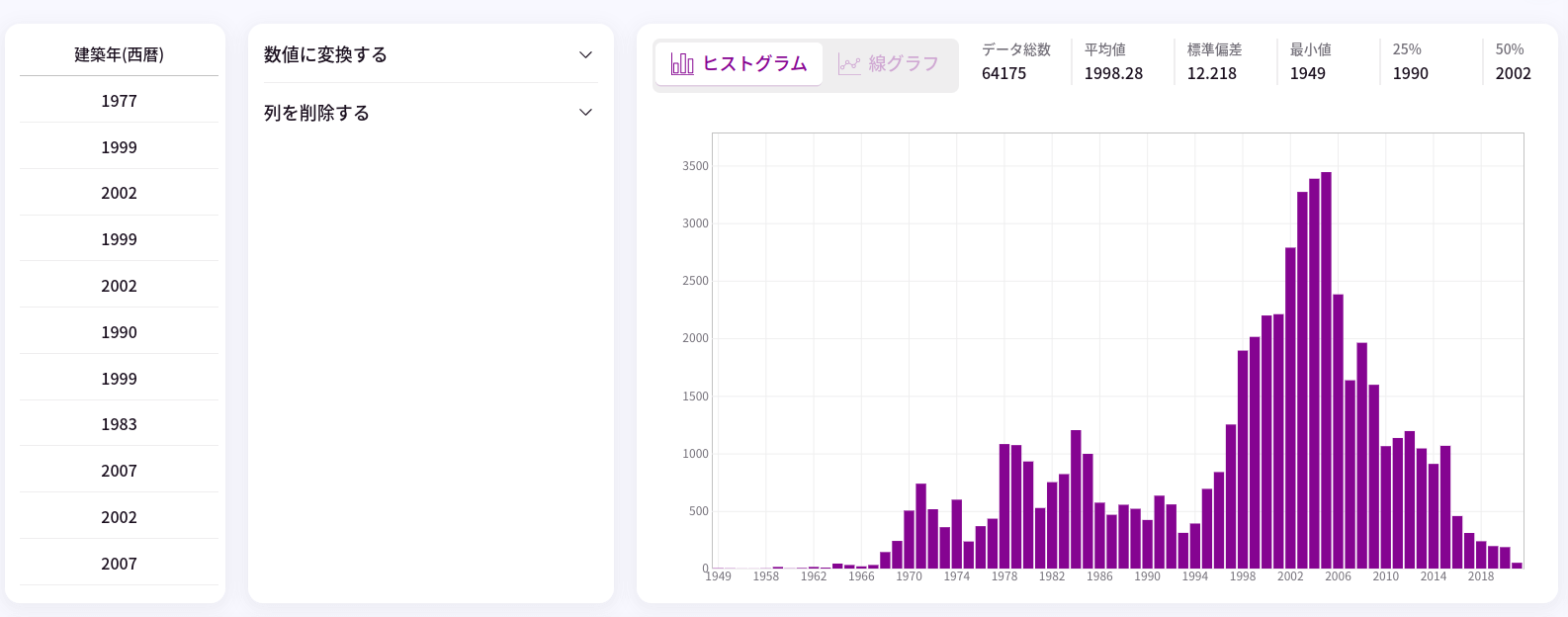
適切に学習ができなかった場合、2000年代半ばのデータは予測できるのに、2022年現在の価格の予測は上手く行かない(2000年台半ばの平均的な価格に引きずられる)ということが推測できます。一方で、上記のような形でデータを取り込んでも将来予測(時系列方向の外挿)は難しいでしょう。学習データには今年の(2022)のデータも多少なりは含まれていますし、今年時点での市況をモデルが汲み取ってくれることは期待できますが、年を追う毎にどのような変化をしているかのトレンドを表現するための構造をモデルに適切に入れてあげなければ、将来予測は容易にはできないでしょう。それでも現時点で販売されている物件の提示価格と比較するという問題には使えると期待して進めます。
3.用いるモデルと学習方法
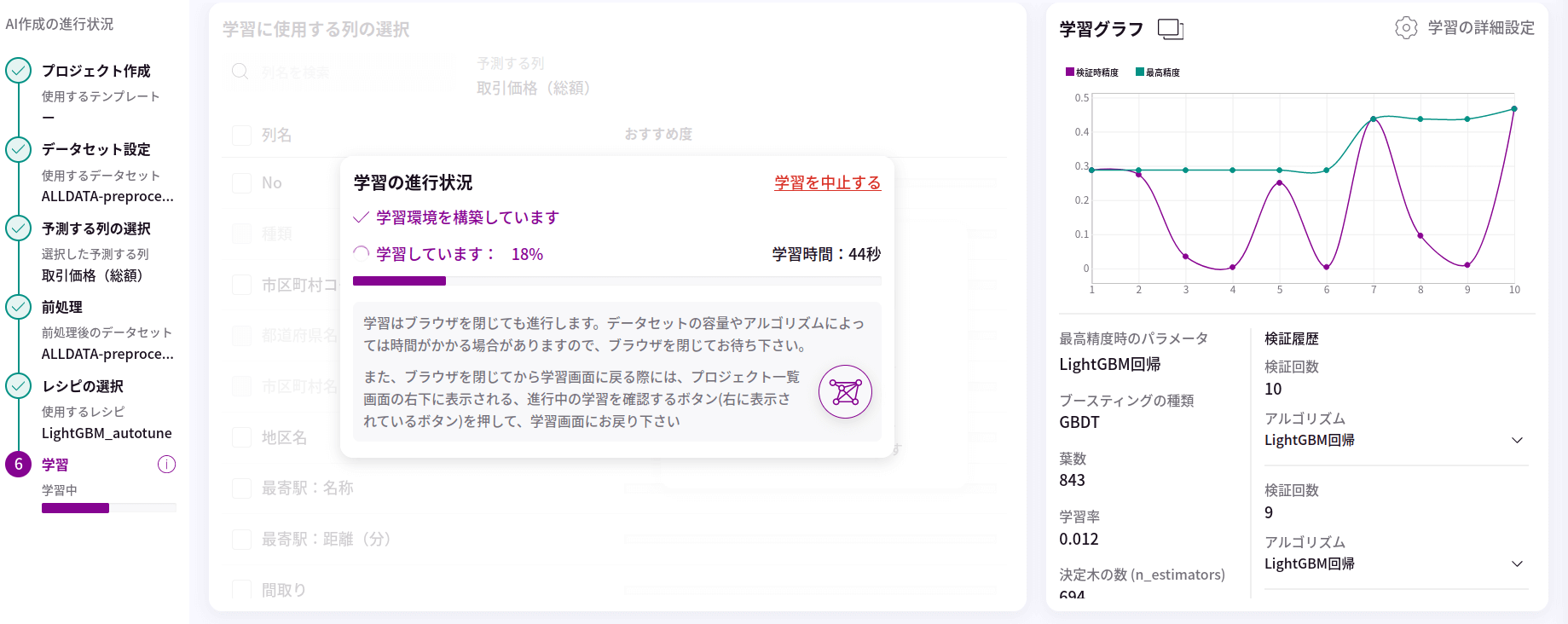
今回はテーブルデータで最も使い勝手の良いとされるGradient Boosting Treeを利用します。その中でも学習データが膨大な場合に短時間で学習が行えるLightGBMを活用します。LightGBMには多数のハイパーパラメータ(学習をするために事前に決めなければいけない設定値)が存在しますが、これらの調整は検証データを用いて行います。

流れとしては、
0.AIの学習の設定値を決める
1.訓練データでAIの学習を行う
2.検証データでAIの評価を行い、学習の設定値と学習済のAIを記録する。
3.十分に検証を繰り返したら終了。そうでなければ「0.」に戻る。
を行い、一番良かった「2.」の評価結果とそのときのAIを選定します(あるいは「0.」で決めた学習の設定値を取り出し、再度、訓練データと検証データを合わせて学習させAIを完成させる)。このスキームでは訓練データはAIの学習用に用いられ、検証データは学習の設定値を決める人間の試行錯誤用に用いられます。
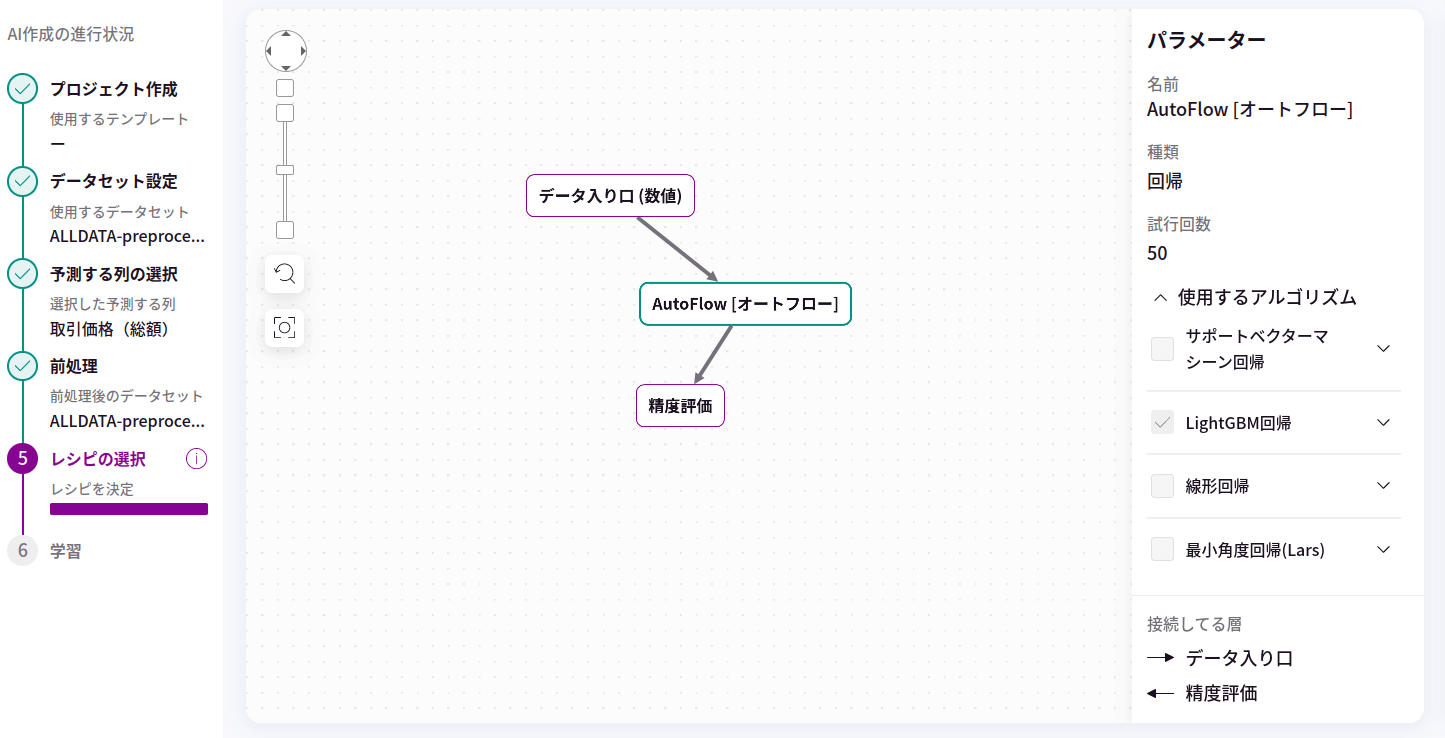
できれば、学習の設定値も試行錯誤ではなく自動で実施してやりたりと思うところで、実際にはベイズ最適化や進化計算を用いたハイパーパラメータの自動チューニング技術が研究および実用されています。今回活用するMatrixFlowでは、モデルの構築および検証データの作成とそれを用いた評価、そしてハイパーパラメータ調整も含む学習のスキームの全てをノーコードで実行可能です。今回はMatrixFlowで提供されるAutoFlowというモデルを利用させてもらいました。AutoFlowでは複数のモデル(例えばLightGBMと関連度自動決定モデルとリッジ回帰モデル)を同時に学習およびハイパーパラメータをチューニングし、良かったモデルを選定してくれます。今回は、特徴量に離散値が多いことと、離散値をint型でラベルエンコーディングしているので、このあたりを上手に扱ってくれるLightGBMのみを活用することにしました。
4.学習結果
MatrixFlowで回帰モデルを学習させると、(学習に用いなかったデータに対する)決定係数によってAIの評価をしてくれます。決定係数とは、手元の正解値とAIの予測値にどれほどの相関があるのかを数値化したものです。0~1の値を持ち、基本的に大きい程手元のデータとAIの予測の一致度が高いと言えます。もし学習に用いなかったデータに対する決定係数が高いのであれば、新規のデータに対してもAIはそこそこ一致する予測値を出せていると信じて利用することができます。直線回帰を例に、どういう場合に決定係数が高いor低いという状態になるかの例を図で表します。
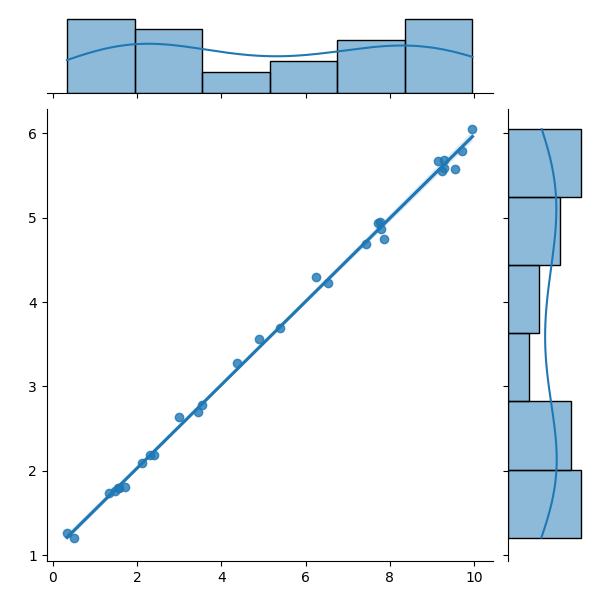
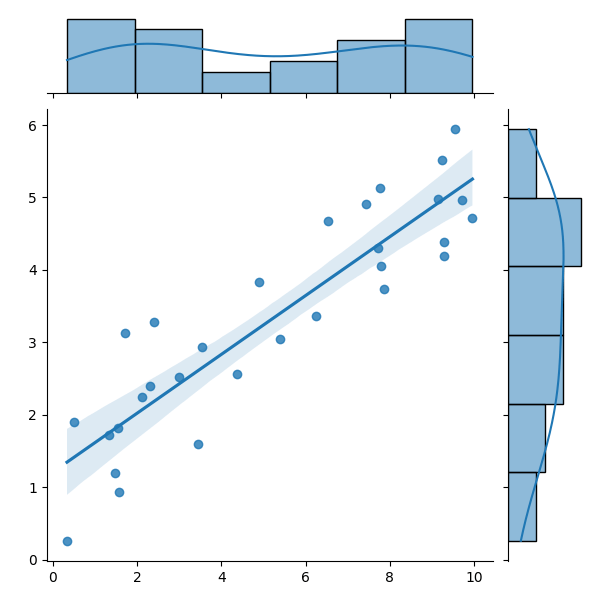
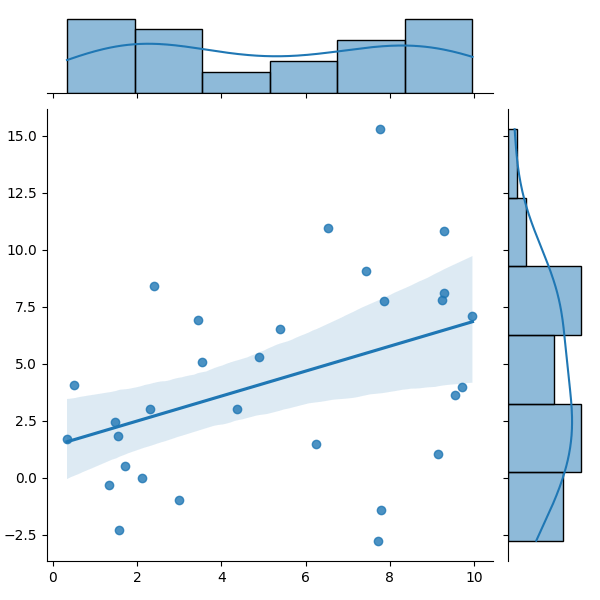
図の通り、上から順に回帰直線上に実データが乗っかっています。回帰線が実データを表現できているほど決定係数は大きくなるということです。重要なこととして訓練データに対する予測値とその正解値の決定係数は高くて当然ということが言えます。AIを直線回帰モデルから複雑なものにしていけば、訓練データの決定係数は大きくしていけます。なので学習に用いてないデータに対する決定係数が重要となります。
また、分野をまたがって決定係数の値によって良し悪しを述べることはできないという点に注意しましょう。例えば決定係数は0~1の値しか取らないので適当に3段階分けて「0~0.5」が悪くて、「0.5〜0.8」が普通で、「0.8~1.0」 が良い、ということは一般的には言えません。例えば、電気抵抗を図るような例で、電圧を印加できる装置で抵抗に電圧を掛け、電流計で電流を計測し、オームの法則を利用して単回帰によって抵抗を計測したとします。そうしたときに、決定係数が0.8台なんて値だったら装置が壊れているか計測の設定を誤ったと思ったほうが良いです(この物理現象はもっと再現性が良いです)。これはすなわち、該当分野に「そもそも特徴量からは取り出せない予測不可能な外乱」がどれほど生じているのかに由来します。なので目安として頭の中に持っておくという以上のことはできないという点に注意しましょう。決定係数は0~1に正規化された基準ですが、今回のケースはもしかしたら、純粋に平均的に何円予測がズレるか、という値とその許容度を心に持っておくのが適切かもしれません。
さて、下記に、今回準備した不動産販売実績データから、AutoFlowによるLightGBMの自動チューニングで得られたAIの評価を各区毎に見ていきます。
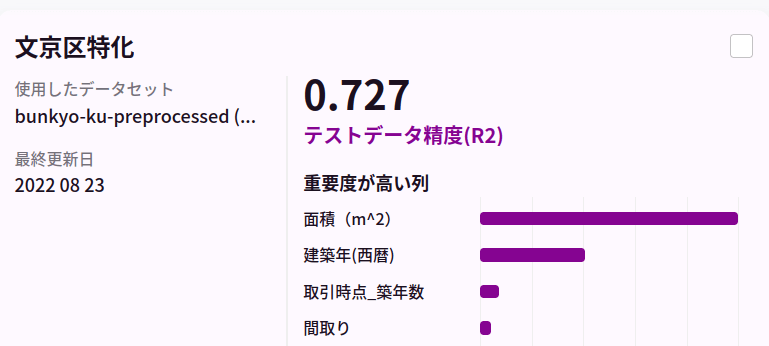
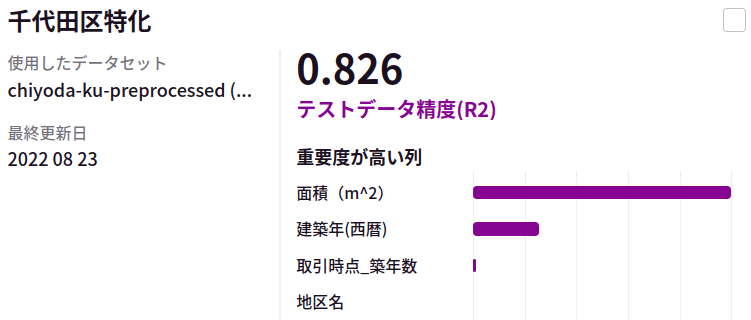
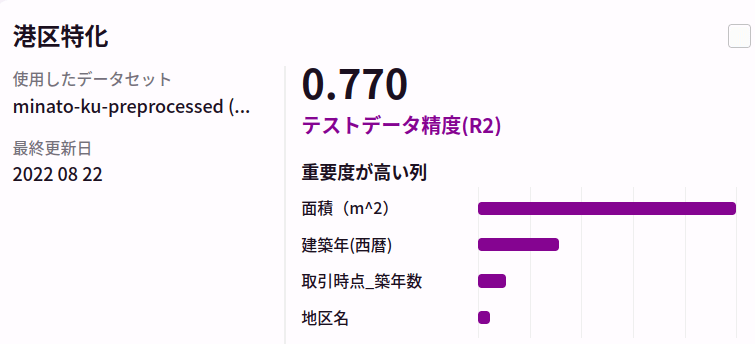
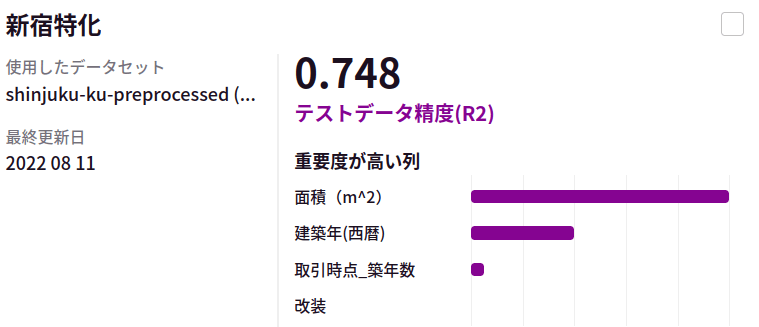

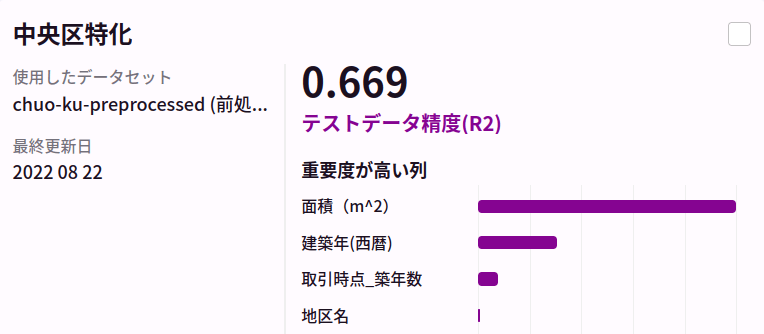
今回は、全く同じ特徴量抽出に対して、全く同じAutoFlowによる仕組みで学習のスキームを回しました。意外と区毎にAIの決定係数が異なっておりました。別途、東京都心部ではない大田区についても同様の方法でモデルを構築、評価を実施しました。
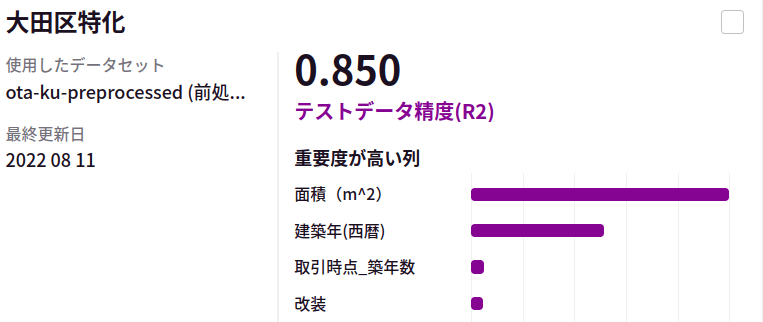
こちらでは東京都心部に比べて比較的精度の良い予測ができていそうです。これだけ、同じモデル、同じ特徴抽出で精度に差が出てくるとなると取り逃している地域差の情報がありそうな気がします。これまで個々の地域に区切っていたデータを全てまとめて学習させたモデルの結果も下記に載せます。
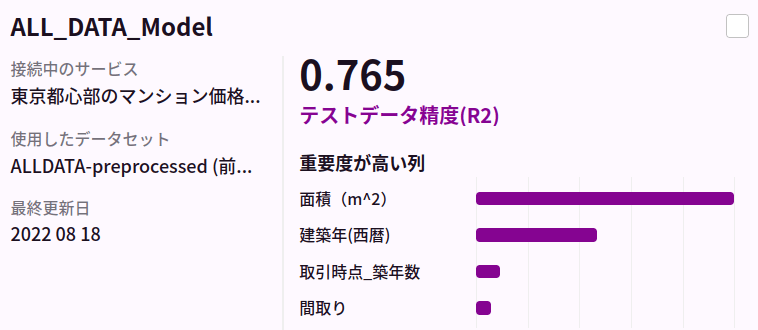
千代田区、中央区、新宿区、渋谷区、港区、中央区、大田区の全てのデータを使ったモデルでは、区毎に学習させたモデルの平均的な性能と同等の結果となりました。地名や駅名を学習データに入れているため、全てのデータを混ぜてしまっても場所が特徴として考慮され、問題なく予測が可能になっていると考えられます(仮に各地区ごとにモデルを作るほうが平均的に性能が良いとすると、地名の情報が正しくモデルに反映されていないと考えられましたが、実際には全部混ぜても精度が劣化しないのだとすると、地区を正しく価格に反映できていないとは考えづらいです)。(特に中央区において)予測を困難にするような劇的な外乱がいると考えることが妥当かもしれません。例えば、今回のマンション価格の予測では「マンションの階数」はデータとして取れていません。それほど大きくないマンションでは階数は効きませんが、高層マンションは明らかに同じ間取りでも高層階の方が価格が高いです。また、他に考えうる外乱としては、売られている物件が「商業用施設」なのか「居住用」なのかの特徴量を用いていなかったため、これらが混在する地域では予測精度が劣化する可能性もあります(実際、商業用のテナントを販売するケースでは壁や設備にお金が掛かってない分安い傾向がありそうです)。課題としては、高層マンションが多いエリアや商業施設やオフィスが多い地域を別途上手に扱う方法を考える必要がありそうです。それらは東京23区すべてを扱ってみればわかってくることがあるかもしれませんが、不動産の専門家ではないので一旦区切るとします。
5.Web上の販売物件を予測してみる
Web上で実際に提示されている物件情報から、全データを混ぜて学習させたAIを使って価格を予測してみます。AIは東京都での実際の取引実績価格を学習させているため、予測値は「取引されるとしたら妥当な価格」となっていることが期待できます。すなわち掲載されている価格よりも取引価格の予測値が高ければ買いな物件であると考えることができます。以下、提示販売価格がWeb上で販売価格として掲載されている価格で、予測価格がモデルの出力する取引されるとしたら妥当だと言える価格となります(今回のモデルはこれまでの説明の通り、特徴量を適当に選定してAutoFlowで学習させてみた中で課題も残っているAIです。AIの予測精度の保証はできませんし、現在売られている物件が実際に割安であるとか割高であるとかを言い切るものではありません。あくまで使い方の一例になります)。
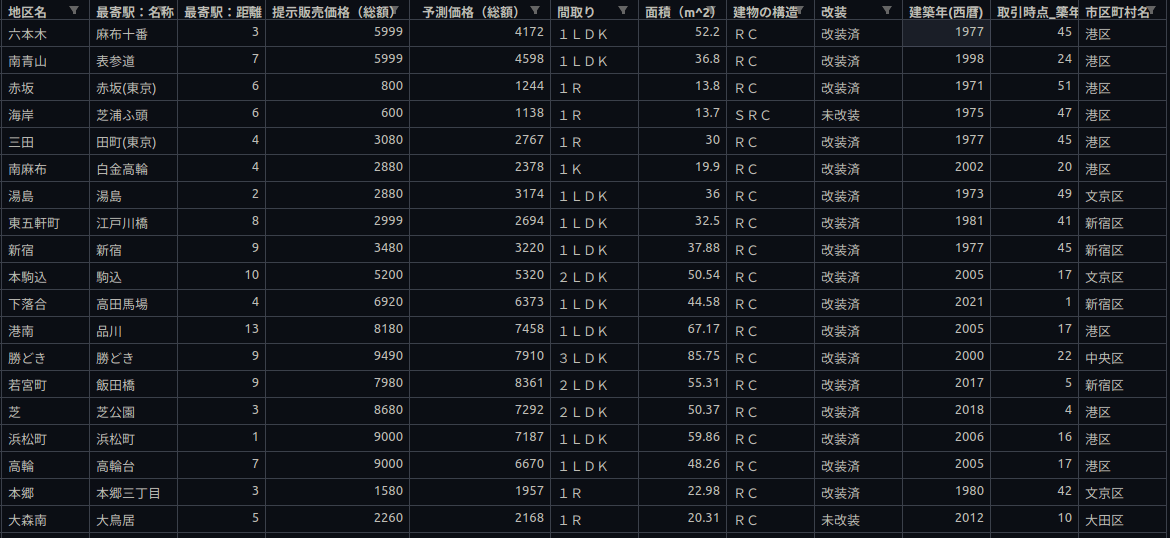
結果をパッと見ると、現在販売されている物件に関しても概ね提示価格との相関がありそうな結果となっています。上記「提示価格(asking price)」と「予測価格(predicted price)」をそれぞれ横軸と縦軸として、実データを下記にプロットしてみます。
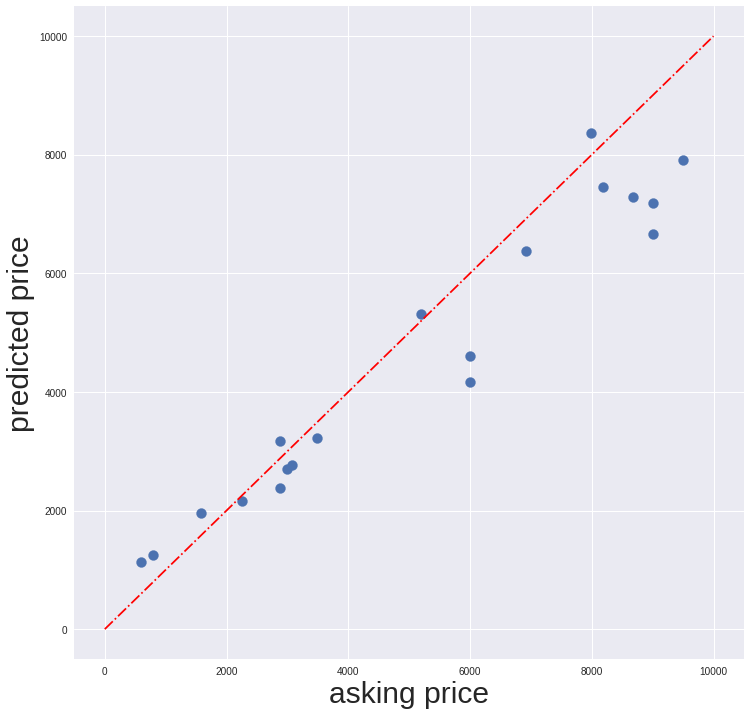
赤のドットラインが y=x のラインになり、このラインより上にあるデータ点が「これまでの販売実績から予測価格が、現在の提示価格を上回っている」ということを表しておりお買い得な物件であると考えることができます。比較的低価格帯の物件のほうがお買い得物件が多そうに見えます。これは適当に筆者が選択した数十件のデータに対しての結果なので、もっと大量のデータを扱ってみると見えてくるものもあるかもしれません。
さて、予測価格と提示価格の乖離が大きい、asking priceが9000万円となっている物件に関しては次のような考察をすることができるかもしれません。キリが良い提示価格であることから直近で売却が開始されたばかりであると考えられる。また提示価格は売却主が決定でき、一般的に随時値下げが行われる。このような観点で現時点では売却主に有利な形で相場からかけ離れた割高な提示価格になっていると考えられそうです。
逆にお得度が高そうなasking priceが2000万円を切っている物件に関しては次の考察ができそうです。ワンルームでかつ築古の物件であり住居用としての用途が限られる。また耐用年数をオーバーしており建物自体を担保として融資を受けるのが難しく、買い手が付きづらい。このような理由から割安な形で相場からかけ離れていそうです(仮に該当物件を買ってどう活用するかは悩ましいですね)。
ある程度の妥当な予測をする上ではテーブルデータとして適切に特徴を作り、LightGBMで予測モデルを作るのは非常に有効な手立てだと感じました。またそれを実行する上でMatrixFlowは非常に手軽にモデルを構築でき、かつデータを取り替えたりした場合の反復的な実験やモデルの管理なども任せることができる点で便利でした。この利便性に支えられ、分析時には問題に集中することができたという実感もありました。
6.まとめと今後の発展
今回のモデルでは「地区名(離散値)、最寄駅(離散値)、駅徒歩(連続値)、間取り(離散値)、面積(連続値)、建物構造(離散値)、改装(離散値)、建築年(連続値)、取引時点の築年数(連続値)」を説明変数としました。建築年と取引時点の築年数、および最寄駅、駅徒歩などの時空間情報はもう少し適切な取り扱い方がありそうです。
例えば、時間情報に関しては適切な他の経済的な指標を同時に扱いながら、他変量の自己回帰結合を入れることで将来予測(Forecast)が可能なモデルを作ることができそうです。また空間情報に関しては駅の名前や地区名という離散的なラベルにしてしまうことで、各地区との位置関係が完全に失われる形になっています。これらを経度や緯度の連続的な空間情報に置き換えることで地区同士の関係性を直接数字で扱えそうです。あるいは離散的なラベル同士の関係性を学習の中に含んでしまうような複雑なモデルを扱うなども考えることができるかもしれません。
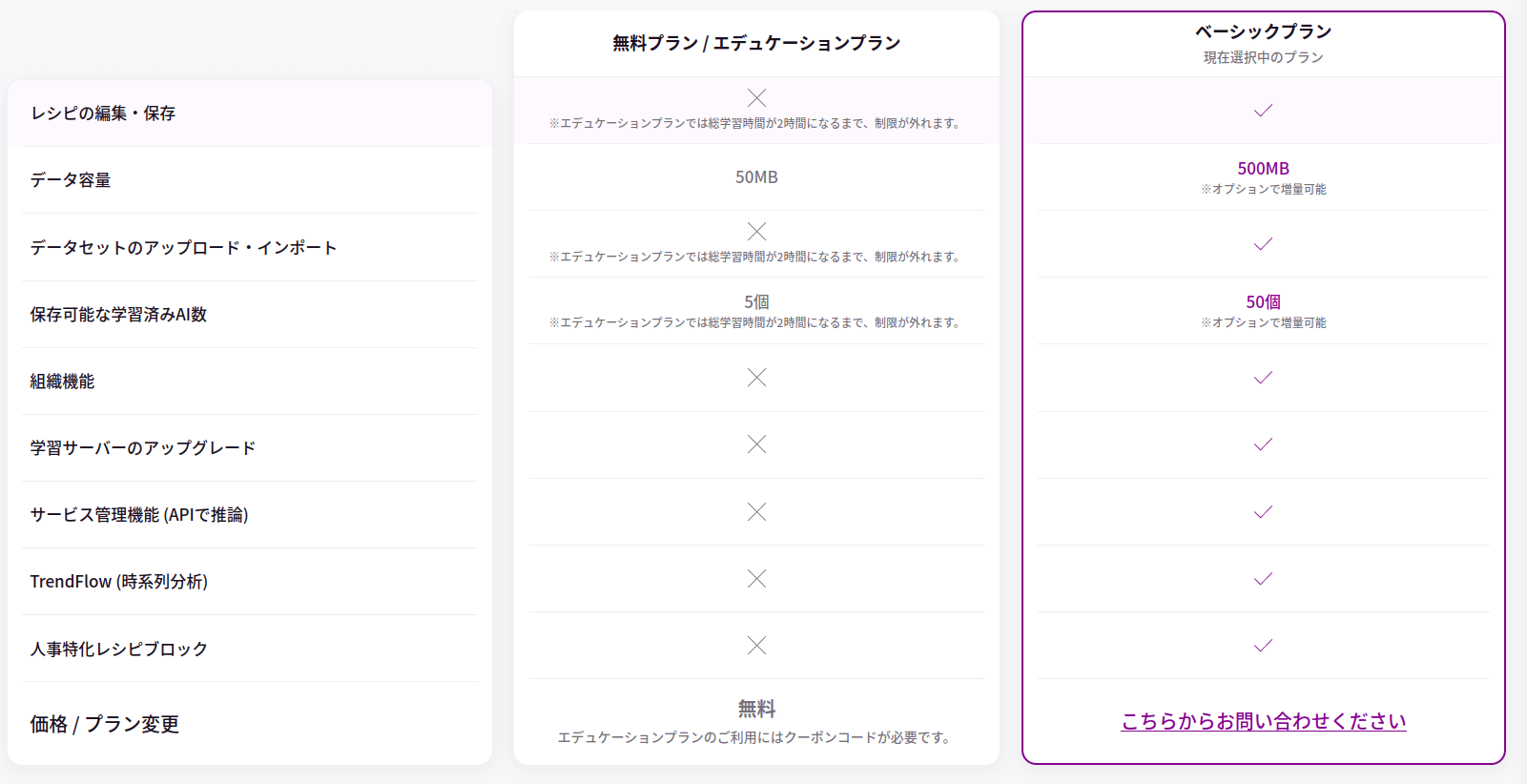
しかし、これらを扱うには問題に応じた適切な特徴量エンジニアリングと各モデルを適切に構築し評価するための非常に専門的な知識と技能が要求されるため、今回はこのあたりで区切りたいと思います。今回は無料でダウンロードできる国土交通省土地総合情報システムのデータとMatrixFlowを使った簡単なマンション価格予測をしてみました。このモデルで自分で不動産売買するぞ!ってほどガチガチにチューニングはしていませんが、ある程度方向性が変では無さそうなAIをすばやく作ることができました。ぜひ皆さんもMatrixFlow無料プランで試してみたください。