このセクションの他の記事
学習用データセットの作り方
学習用データセットの作り方をデータ種類ごとに解説します。
推論用のデータセットの作り方は学習用に準じますが、一部異なる点もあるため、推論用データセットの作り方 をご覧ください。
■数値や文字列データの表形式CSVファイルの作成
データの内容は数値や文字列で、行と列で構成される表形式のデータです。横1行で1つのデータ(1サンプル)です。構造化データやテーブルデータとも呼ばれます。
このタイプのデータは、分類や回帰、時系列解析が行えます。
ここで言う「文字列」とは、値をルールに従って数値に変換できる文字列を指します。変換ルールはいくつかありますが、何らかのルールでグルーピングできることが条件です。例えば「女」を0「男」を1「その他」を2 に置き換えるなどです。
文字列を「予測する列」や「学習に使用する列」として使うには 数値に変換する必要がありますが、この処理は後工程の「前処理」で可能ですので、データ作成時に変換しておく必要はありません。
「前処理」について詳しくは、学習中の前処理画面 をご覧ください。
<データの作成方法>
1.表計算ソフト(Microsoft ExcelやGoogle スプレッドシート など)でデータを入力します。
2.ファイルを保存する際、ファイル形式に「カンマ区切りのcsv」を指定して保存します。
<データ作成時の留意事項>
・1行目に列名を必ず設定します。
列名がなく値だけの列がある場合、アップロード時に「名前が設定されていない列があります」とエラーが表示されてアップロードできません。
また、列名が設定されていない列は、アップロード画面のデータプレビューで「Unnamed: n」と表示されます。
・文章など、単純に数値に置き換えできない文字列も「学習に使用する列」に使えます。
この場合、レシピに自然言語処理を組み込むと、文章を数値化して処理を行います。(詳細は次項「■単語や文章を含む表形式CSVファイルの作成(自然言語を含む構造化データ)」を参照)
・時系列(日付)の列は昇順に並べてください。等間隔のデータを用意してください。(1日であれば1日間隔に、1時間であれば1時間間隔に。昇順にデータを入力します。)
※列名は、
<データ作成例>
下図は分かりやすいように[予測する列:赤][学習に使用する列:紫][学習に使わない列:灰色]に色付けしています。
・データにはAIモデルの構築に不要な列が含まれていても差し支えありません。
・「性別」列は学習に使用するため、後工程の前処理で数値に変換します。
※データ作成の際、色付けを行う必要はありません。
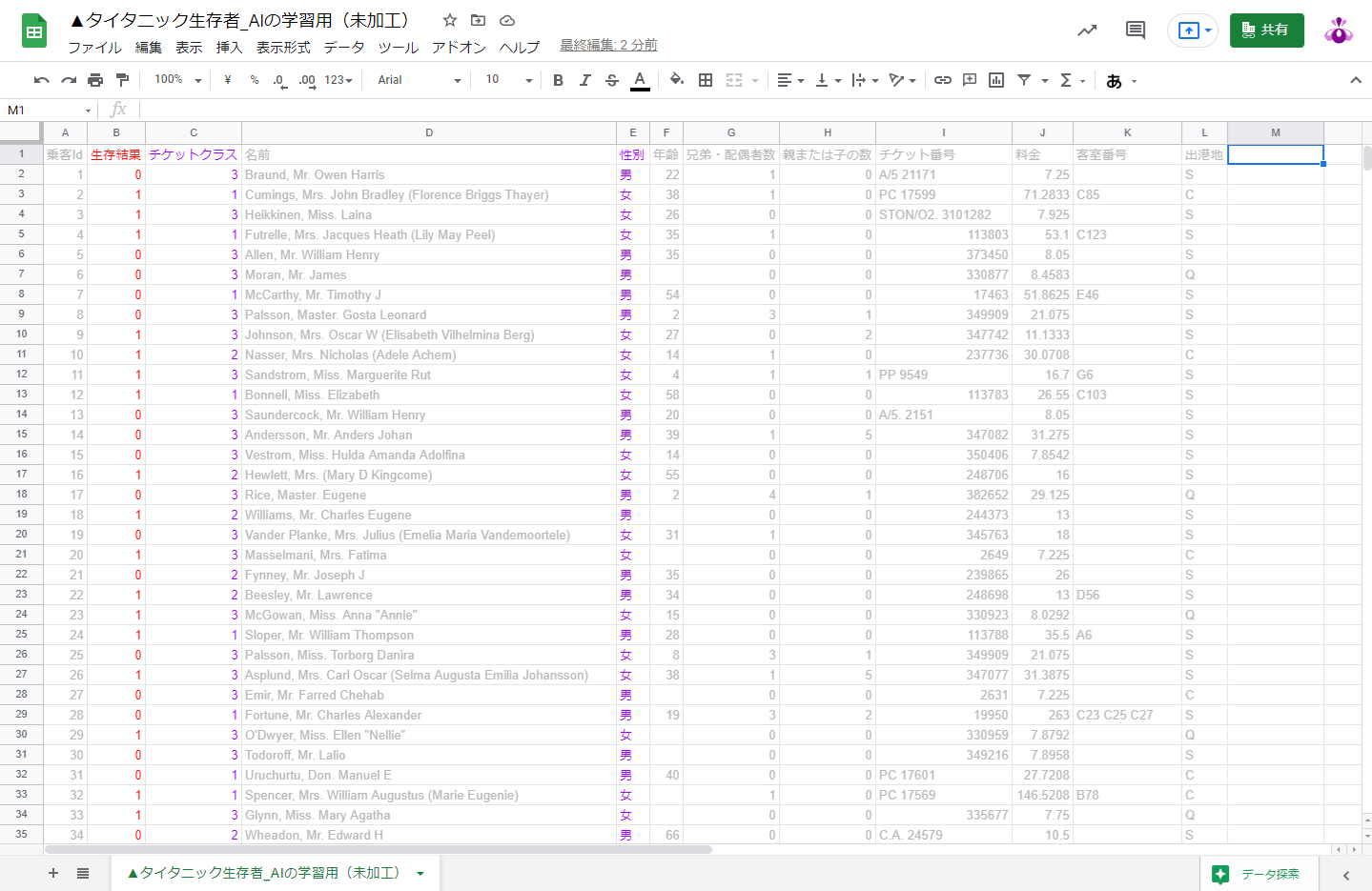
以下は、上図のデータをCSVファイル形式で保存した事例です。(冒頭10行のみ抜粋)
乗客Id,生存結果,チケットクラス,名前,性別,年齢,兄弟・配偶者数,親または子の数,チケット番号,料金,客室番号,出港地
1,0,3,"Braund, Mr. Owen Harris",男,22,1,0,A/5 21171,7.25,,S
2,1,1,"Cumings, Mrs. John Bradley (Florence Briggs Thayer)",女,38,1,0,PC 17599,71.2833,C85,C
3,1,3,"Heikkinen, Miss. Laina",女,26,0,0,STON/O2. 3101282,7.925,,S
4,1,1,"Futrelle, Mrs. Jacques Heath (Lily May Peel)",女,35,1,0,113803,53.1,C123,S
5,0,3,"Allen, Mr. William Henry",男,35,0,0,373450,8.05,,S
6,0,3,"Moran, Mr. James",男,,0,0,330877,8.4583,,Q
7,0,1,"McCarthy, Mr. Timothy J",男,54,0,0,17463,51.8625,E46,S
8,0,3,"Palsson, Master. Gosta Leonard",男,2,3,1,349909,21.075,,S
9,1,3,"Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg)",女,27,0,2,347742,11.1333,,S
10,1,2,"Nasser, Mrs. Nicholas (Adele Achem)",女,14,1,0,237736,30.0708,,C
・・・CSVファイルは、表計算ソフトを使わず、テキストエディタ(Windowsのメモ帳やMacのテキストエディットなど)を使い、列の区切りに「半角カンマ」を入力しても作成することができます。
この方法で作成するとき、文字列内にデータとしての半角カンマがある場合は、文字列全体を「ダブルクォーテーション」で囲います。(参考:上事例内の名前列)
■列名の禁止事項
列名には、下記の文言を避けてご利用ください。
” , [ ] { } :
■単語や文章を含む表形式CSVファイルの作成(自然言語を含む構造化データ)
上述の数値や文字列で構成される表形式データに加え、ルールによって数値に変換できない単語や文章が含まれる表形式のデータです。
例えば、アンケートの回答などがこのタイプのデータに該当します。選択形式の設問が数値や文字列、ご意見など記述式の設問が文章にあたります。
このタイプのデータは、分類が行えます。
ルールで変換できない文字列は、レシピに「自然言語処理」のブロックを組み込んで数値化します。
「自然言語処理」についてここで詳細な解説はしませんが、大まかに言うと文章を最小単位の単語に分解し、それをアルゴリズムによって数値化する処理です。
<データの作成方法>
数値や文字列で構成される表形式データに、単語や文章の列が含まれるだけです。
■文書や画像のZIPファイルの作成
上述のCSV形式の文書データとの違いは、1つの文書ファイルが1つのデータ(1サンプル)という点です。このようなデータを非構造化データとも呼びます。
非構造化データの文書や画像は、CSV形式のように1ファイルで複数のサンプルを扱えないため、1ファイルずつのサンプルをZIPファイルとして1つにまとめて投入します。
このタイプのデータは、分類とベクトル化、画像データのみ次元圧縮も行えます。
文書データと画像データのZIPファイルは、フォルダ構造やフォルダ名にルールがあります。
フォルダ構造が適切ではない場合、MatrixFlowは正常に動作できずデータのアップロードに失敗します。
フォルダ構造には、分類カテゴリに相当する「labelsフォルダなし/あり」の2通りありますが、作成しやすい方で差し支えありません。
▶文書データのZIPファイル構造
<labelsフォルダなし>
任意のフォルダ \ 「texts」フォルダ \ ラベル(分類カテゴリ)フォルダ \ 文書ファイル(.txt, .pdf)
・最上位階層のフォルダ名は任意です。
・2階層目のフォルダ名は「texts」固定です。
・3階層目のフォルダ名は「各分類カテゴリの名前」です。
データはこのフォルダの名前に分類されます。
・「各分類カテゴリ」フォルダの中に、そのカテゴリに属する文書データの .txtファイルや .pdfファイルを配置します。
※.txtや.pdfの前のファイル名に”.”(ドッド)は使わないでください。
最上位階層のフォルダをZIP圧縮します。
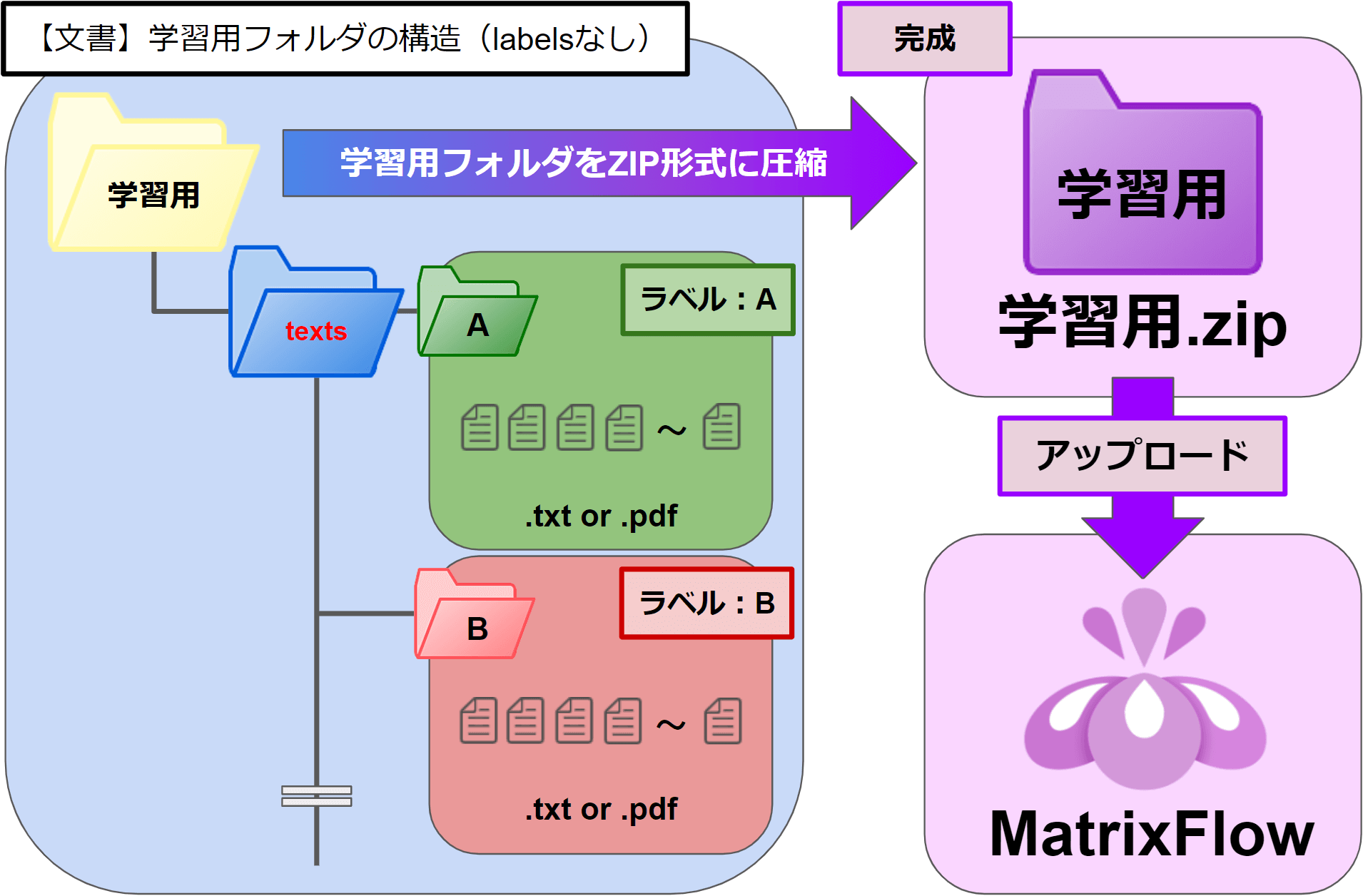
<データ作成例>
Bのフォルダ名を「B新聞社」とします。
「B新聞社」フォルダにB新聞社の記事(.txtファイル)を配置します。
AIは、B新聞社フォルダ内のTXTファイルをB新聞社の記事として学習します。
そのため、B新聞社のフォルダにA新聞社の記事(.txtファイル)を入れてしまうと、A新聞社の記事もB新聞社の記事と判断してしまうAIができあがります。
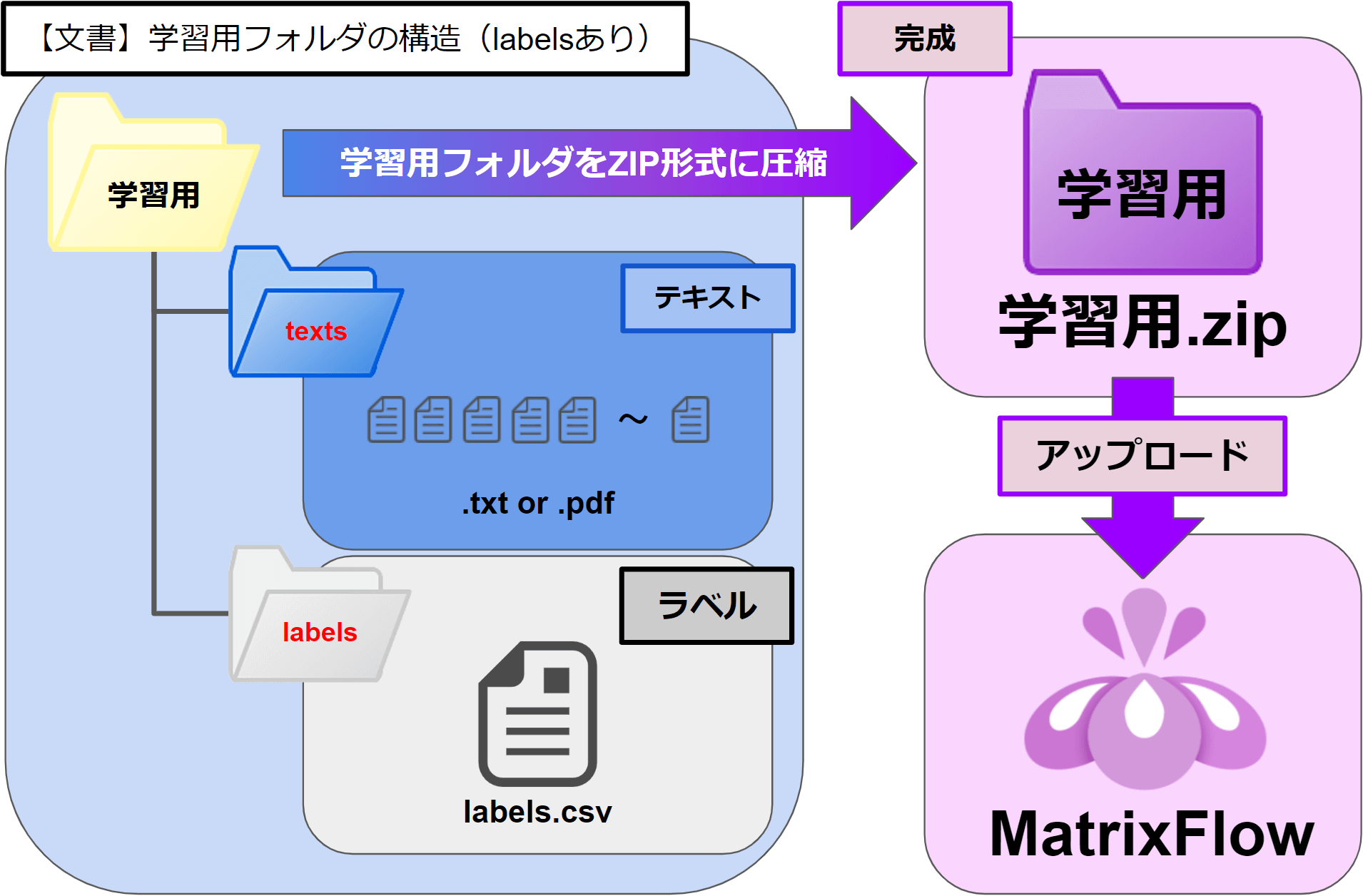
<labelsフォルダあり>
任意のフォルダ \ 「texts」フォルダ \ 文書ファイル(.txt, .pdf)
└ \ 「labels」フォルダ \ 「labels.csv」ファイル
・最上位階層のフォルダ名は任意です。
・2階層目のフォルダ名は「texts」と「labels」固定です。
・「texts」フォルダの中に、文書データの .txtファイルや .pdfファイルを配置します。
・「labels」フォルダの中に、「labels.csv」ファイルを配置します。
labels.csvファイルは、文書ファイル名とその文書の分類カテゴリだけを記述したCSVファイルです。
※.txtや.pdfの前のファイル名に”.”(ドッド)は使わないでください。
最上位階層のフォルダをZIP圧縮します。
<labels.csvファイルの作成事例> 列名は不要です。
news_5978741.txt,movie-enter
news_4778626.txt,peachy
news_6712738.txt,smax
news_6793390.txt,it-life-hack
news_6306081.txt,topic-news
news_6727600.txt,dokujo-tsushin
news_6251811.txt,sports-watch
news_5955767.txt,topic-news
news_5888941.txt,kaden-channel
news_6482392.txt,it-life-hack
news_5892868.txt,livedoor-homme
news_6273148.txt,movie-enter
・・・▶画像データのZIPファイル構造
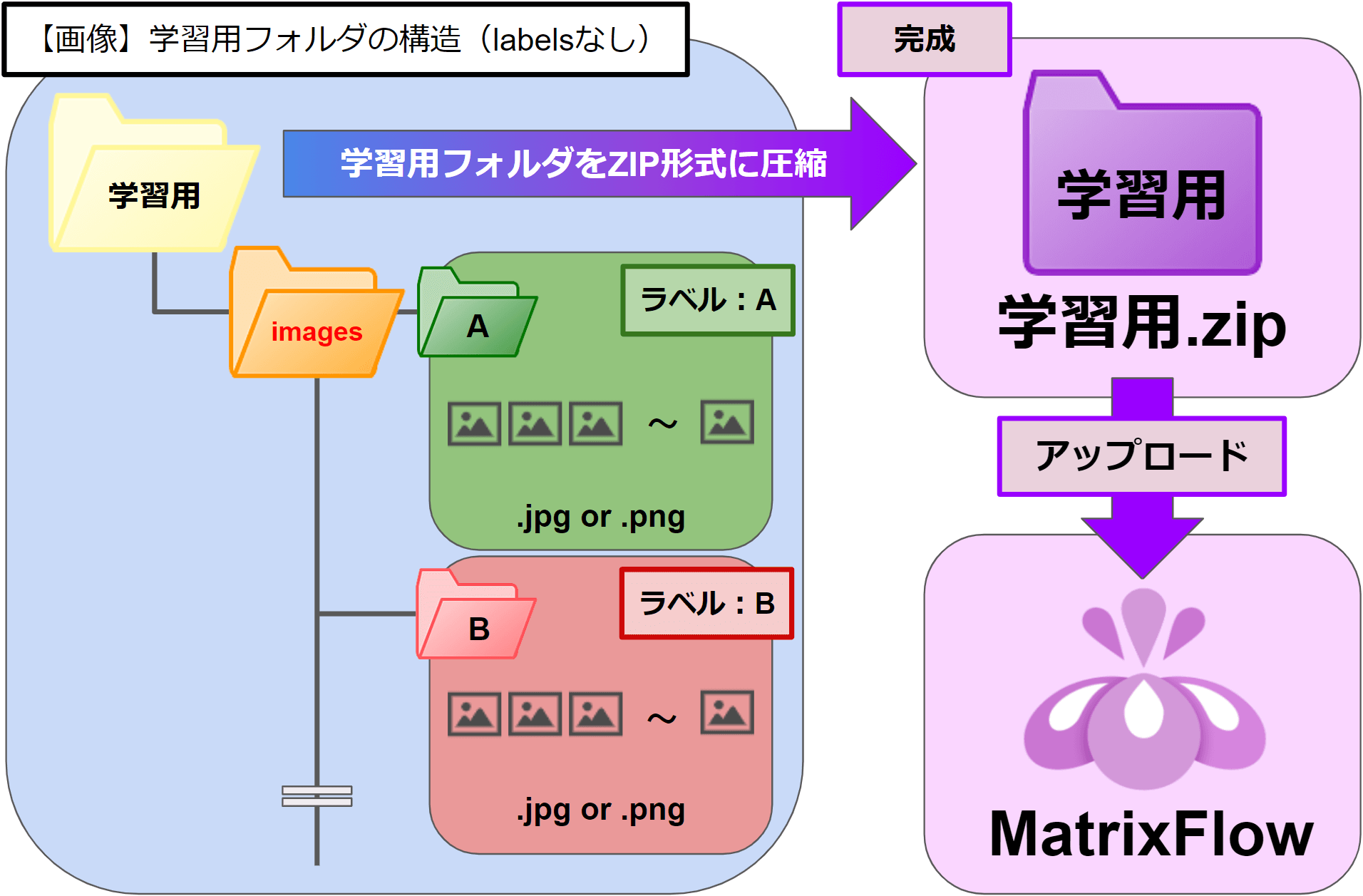
<labelsフォルダなし>
任意のフォルダ \ 「images」フォルダ \ ラベル(分類カテゴリ)フォルダ \ 画像ファイル(.jpg, .png)
・最上位階層のフォルダ名は任意です。
・2階層目のフォルダ名は「images」固定です。
・3階層目のフォルダ名は「各分類カテゴリの名前」です。
データはこのフォルダの名前に分類されます。
・「各分類カテゴリ」フォルダの中に、そのカテゴリに属する画像データの .jpgファイルや .pngファイルを配置します。
最上位階層のフォルダをZIP圧縮します。
<データ作成例>
Bのフォルダ名を「猫」とします。
「猫」フォルダに猫の画像を配置します。
AIは、猫フォルダ内の画像を猫として学習します。
そのため、猫のフォルダに犬の画像を入れてしまうと、犬の画像も猫と判断してしまうAIができあがります。
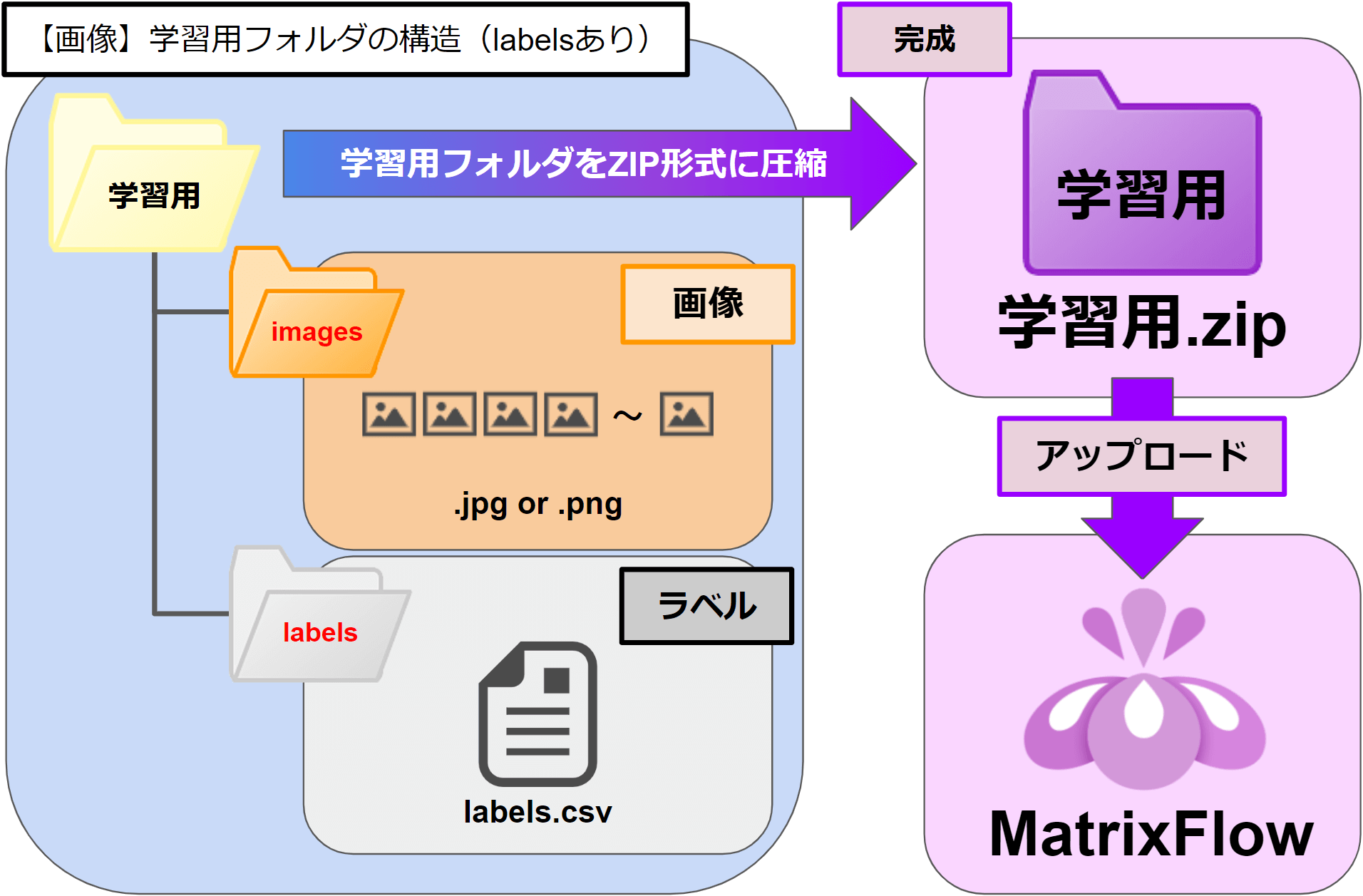
<labelsフォルダあり>
任意のフォルダ \ 「images」フォルダ \ 画像ファイル(.jpg, .png)
└ \ 「labels」フォルダ \ 「labels.csv」ファイル
・最上位階層のフォルダ名は任意です。
・2階層目のフォルダ名は「images」と「labels」固定です。
・「images」フォルダの中に、画像データの .jpgファイルや .pngファイルを配置します。
・「labels」フォルダの中に、「labels.csv」ファイルを配置します。
labels.csvファイルは、画像ファイル名とその画像の分類カテゴリだけを記述したCSVファイルです。
最上位階層のフォルダをZIP圧縮します。
<labels.csvファイルの作成事例> 列名は不要です。
image_0.jpg,ブーツ
image_1.jpg,Tシャツ・トップ
image_2.jpg,ドレス
image_3.jpg,プルオーバー
image_4.jpg,スニーカー
image_5.jpg,ブーツ
image_6.jpg,サンダル
image_7.jpg,ズボン
image_8.jpg,シャツ
image_9.jpg,コート
image_10.jpg,バッグ
・・・▶文書データ、画像データのZIPファイル共通仕様
・ZIPファイル名、フォルダ名に使える文字列
いずれも、半角英数字(a-z, A-Z, 0-9)とアンダースコア( _ )のみです。
特殊文字や全角文字は使用できません。
▶RAG起動用のデータ構造
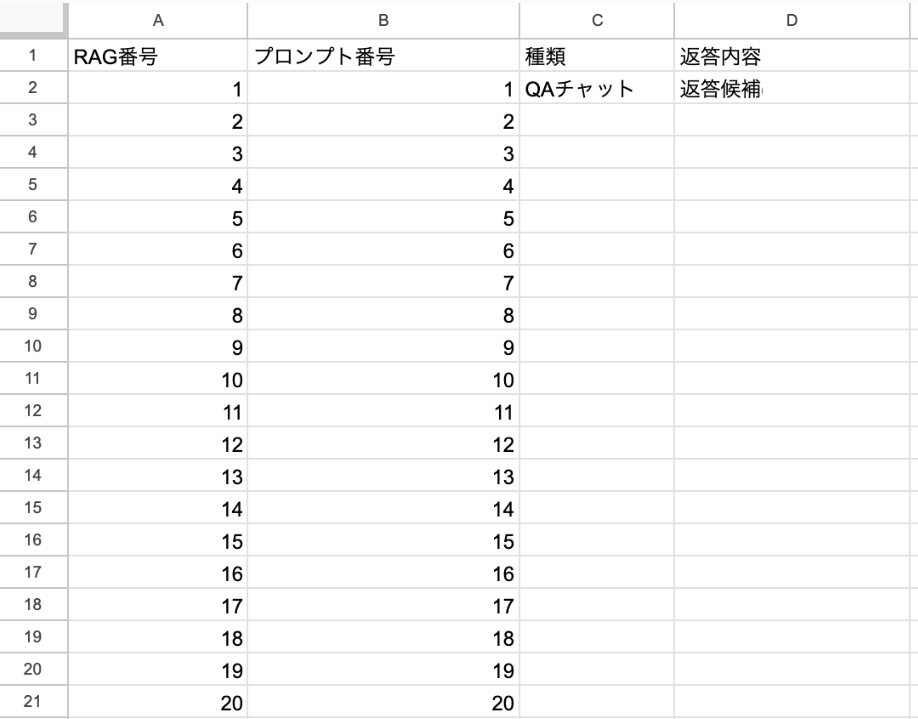
RAGの起動には、決められたデータを用意する必要があります。
データセット設定で「初期設定.csv」を使用する事でRAGが起動します。
・ファイル名は「初期設定」で固定(.csv形式)
・「RAG番号」と「プロンプト番号」も固定。
・1~20まで必ずつける。
・「種類」も「QAチャット」で固定。
・「返答内容」は「返答候補」で固定。
・RAG番号が1,プロンプト番号が1と同じ列に置くこと。
・それ以降の列は空にすること。
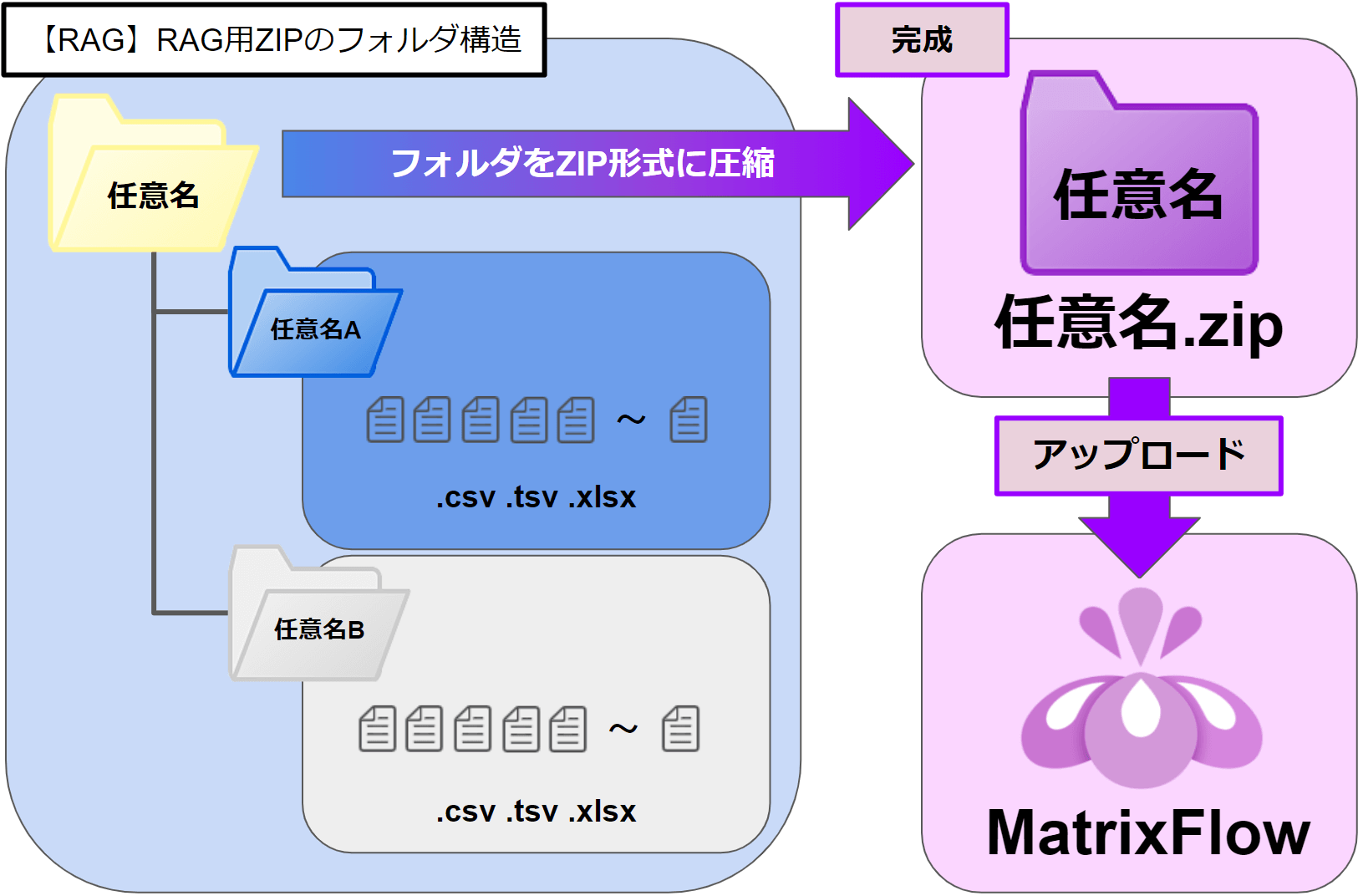
▶RAG用のZIPファイル構造
RAGを起動した後、「質問と回答」の内容が入った圧縮されたデータセット(.csv / .tsv / .xlsx)をアップロードして、質問に対してAIが会話(回答)できるようにします。
・フォルダを圧縮すること。
(データそのものを圧縮しないでください)
・任意名にはお好きな名前が設定できます。