このセクションの他の記事
推論用データセットの作り方
推論用データセットの作り方をデータ種類ごとに解説します。
学習用データセットについては、学習用データセットの作り方 をご覧ください。
■数値や文字列データの表形式CSVファイル
■単語や文章を含む表形式CSVファイルの作成(自然言語を含む構造化データ)
<データの作成方法>
学習用データセットに準じます。
<データ作成時の留意事項>
学習用データセットに準じますが、さらに以下についてご留意ください。
・列名は学習用データセットとまったく同じに設定します。(完全一致)
推論は、AIモデル構築時に指定した[学習に使用する列]の列名を検索してデータを読み込みます。そのため、推論用データセット内に必要な列が見つからないと「データセットに推論に必要な列、または前処理に必要な列が不足しています」とエラーが表示されて推論できません。
・推論用データセットに[予測する列]は不要です。
学習用データセットには、各サンプルの正解にあたる[予測する列]が必須ですが、推論用データセットには不要です。
■文書や画像のZIPファイルの作成
文書データと画像データのZIPファイルに、フォルダ構造やフォルダ名のルールがあるのは学習用データセットと同様ですが、推論用データセットには「labelsフォルダ」は不要です。
フォルダ構造が適切ではない場合、MatrixFlowは正常に動作できず、推論に失敗します。
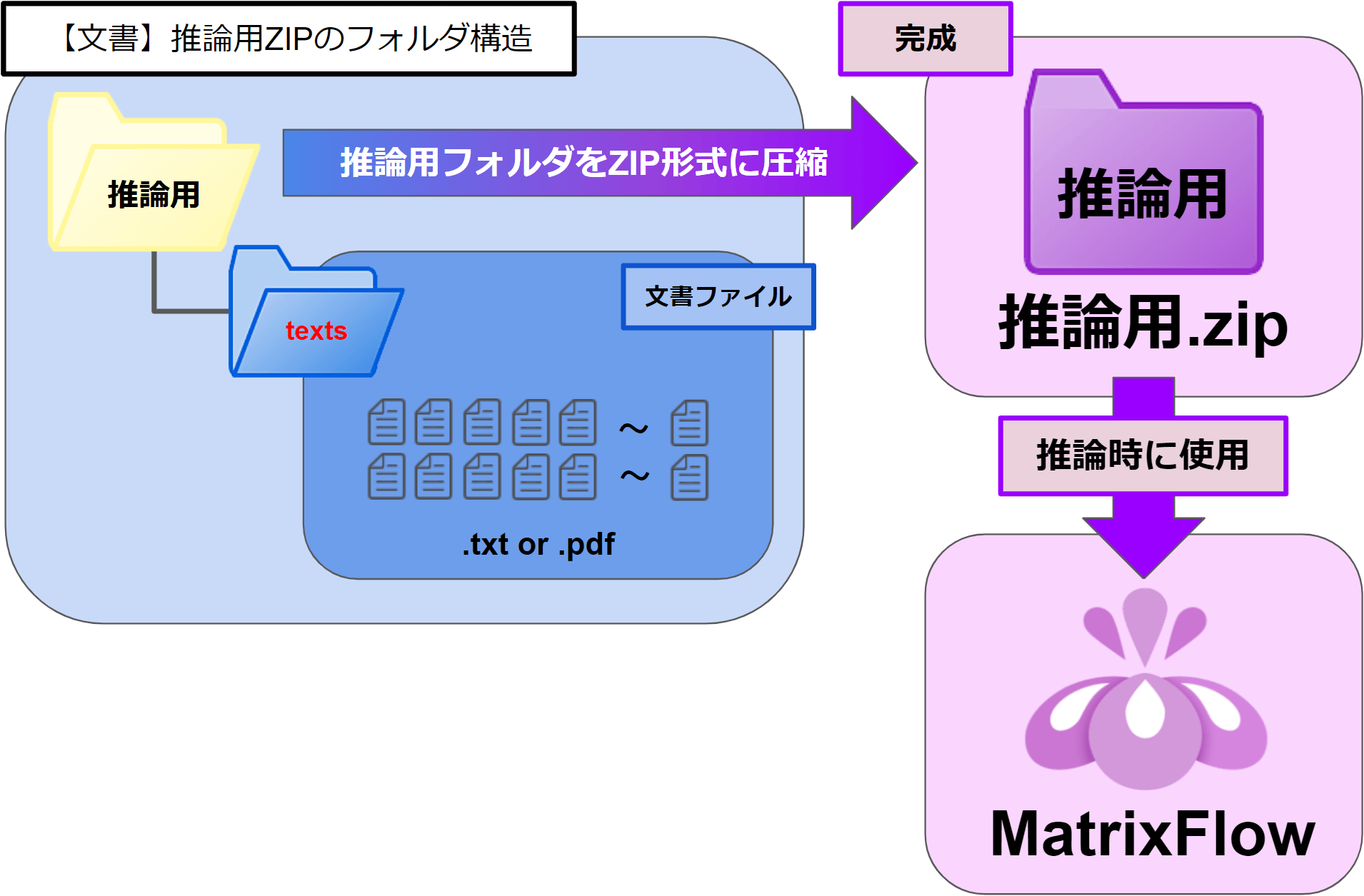
▶文書データのZIPファイル構造
<ZIPファイル内のフォルダ構造>
任意のフォルダ \ 「texts」フォルダ \ 文書ファイル(.txt, .pdf)
・最上位階層のフォルダ名は任意です。
・2階層目のフォルダ名は「texts」固定です。
・「texts」フォルダの中に文書データの .txtファイルや .pdfファイルを配置します。
最上位階層のフォルダをZIP圧縮します。
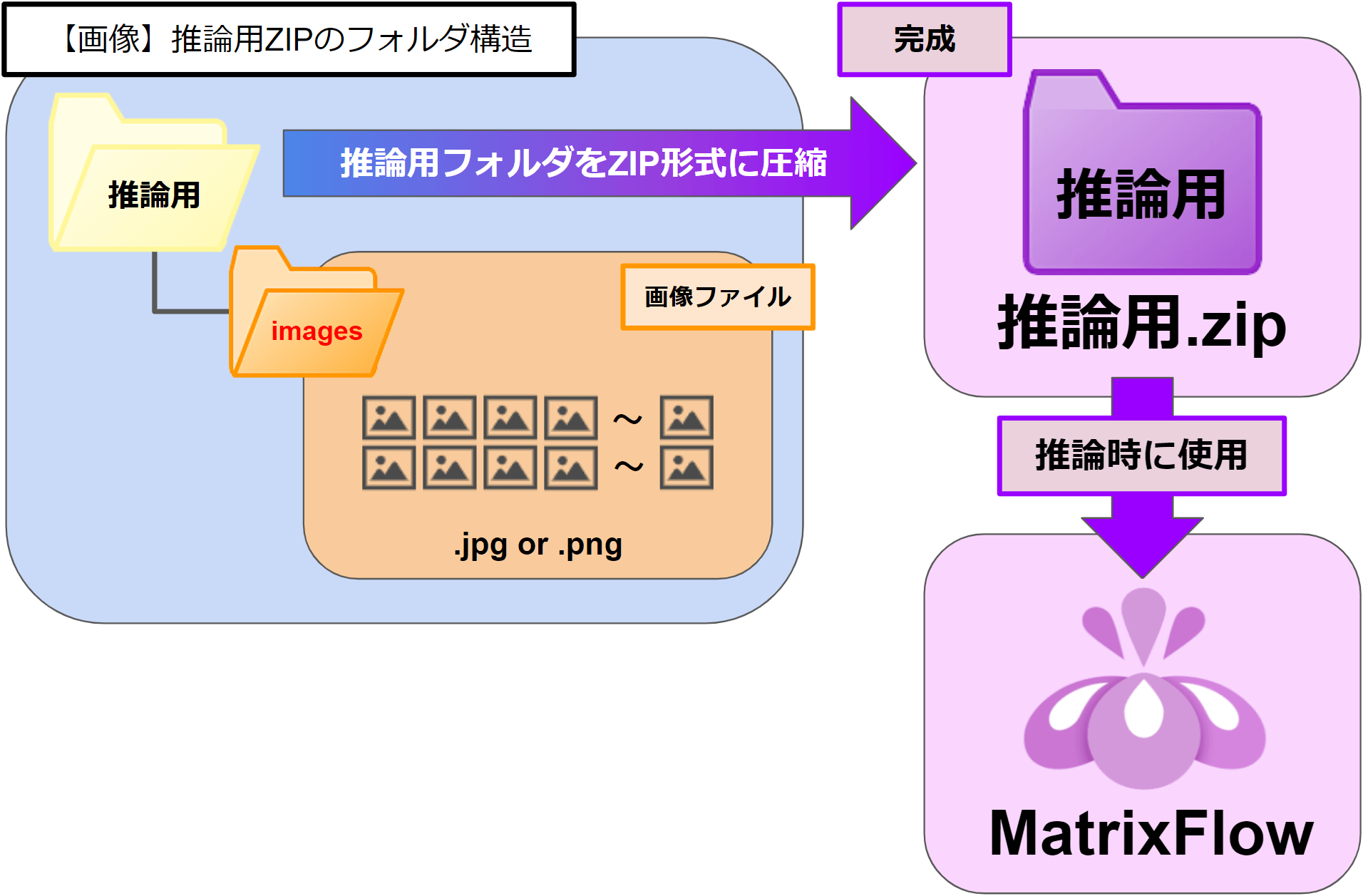
▶画像データのZIPファイル構造
<ZIPファイル内のフォルダ構造>
任意のフォルダ \ 「images」フォルダ \ 画像ファイル(.jpg, .png)
・最上位階層のフォルダ名は任意です。
・2階層目のフォルダ名は「images」固定です。
・「images」フォルダの中に画像データの .jpgファイルや. pngファイルを配置します。
最上位階層のフォルダをZIP圧縮します。
■文書データ、画像データのZIPファイル共通仕様
・ZIPファイル名、フォルダ名に使える文字列
いずれも、半角英数字(a-z, A-Z, 0-9)とアンダースコア( _ )のみです。
特殊文字や全角文字は使用できません。
・推論用のフォルダ構造に、ラベル(分類カテゴリ)のフォルダは不要です。
学習用データセットには、分類カテゴリに相当するフォルダがあったり、分類カテゴリが記述されたファイルを格納するlabelsフォルダが必要ですが、推論用データセットには不要です。
■1ファイルのみで推論を行う
文書データと画像データの分類に限り、ZIPファイルを作成せずに1ファイルのみ投入して推論を行うことができます。
1ファイルで推論できるファイルの種類は次の通りです。
PDFファイルは対応していませんのでご注意ください。
・文書データ(.txt)
・画像データ(.jpg, .png)
■MFTransformerV2(時系列)特有の作り方
レシピブロック「MFTransformerV2」を使用した予測を行う場合、特殊な推論データセットを作ります。
MFTransformerV2で使用する学習データセットと推論データセットの比較図を用いて解説します。

左が「学習データセット」右が「推論データセット」です。途中の行は、省略しています。
<時間列と、その間隔について>
時間のデータ(画像では「公表_年月日」列)は昇順に、等間隔にデータを入力します。
推論データセットは、学習データセットと同じ間隔にする必要があります。
同一のデータセット内で別々の間隔を使用することはできません。
画像上は日間隔ですが、年月日時分秒が利用できます。
<推論データセットの特徴について>
1.画像の640行から647行(8行分)が、予測したい行です。
都道府県列や東京都人口(万人)などの一部の列が予め入力されています。これは、学習の画面にて「予測時に設定できる値か」を「設定できる」にしたためです。
MFTransformerV2は予測時に設定できる値も加味して、予測の結果を出力します。
一方、「予測時に設定できる値か」を「設定できない」にした箇所は空白にします。
MFTransformerV2の推論データセットは「学習データセットに予測したい行のデータを加えたもの」と覚えて頂けますと幸いです。