このセクションの他の記事
前処理における便利な機能で、データ変換があります。
■データ変換機能(スケーリング)とは
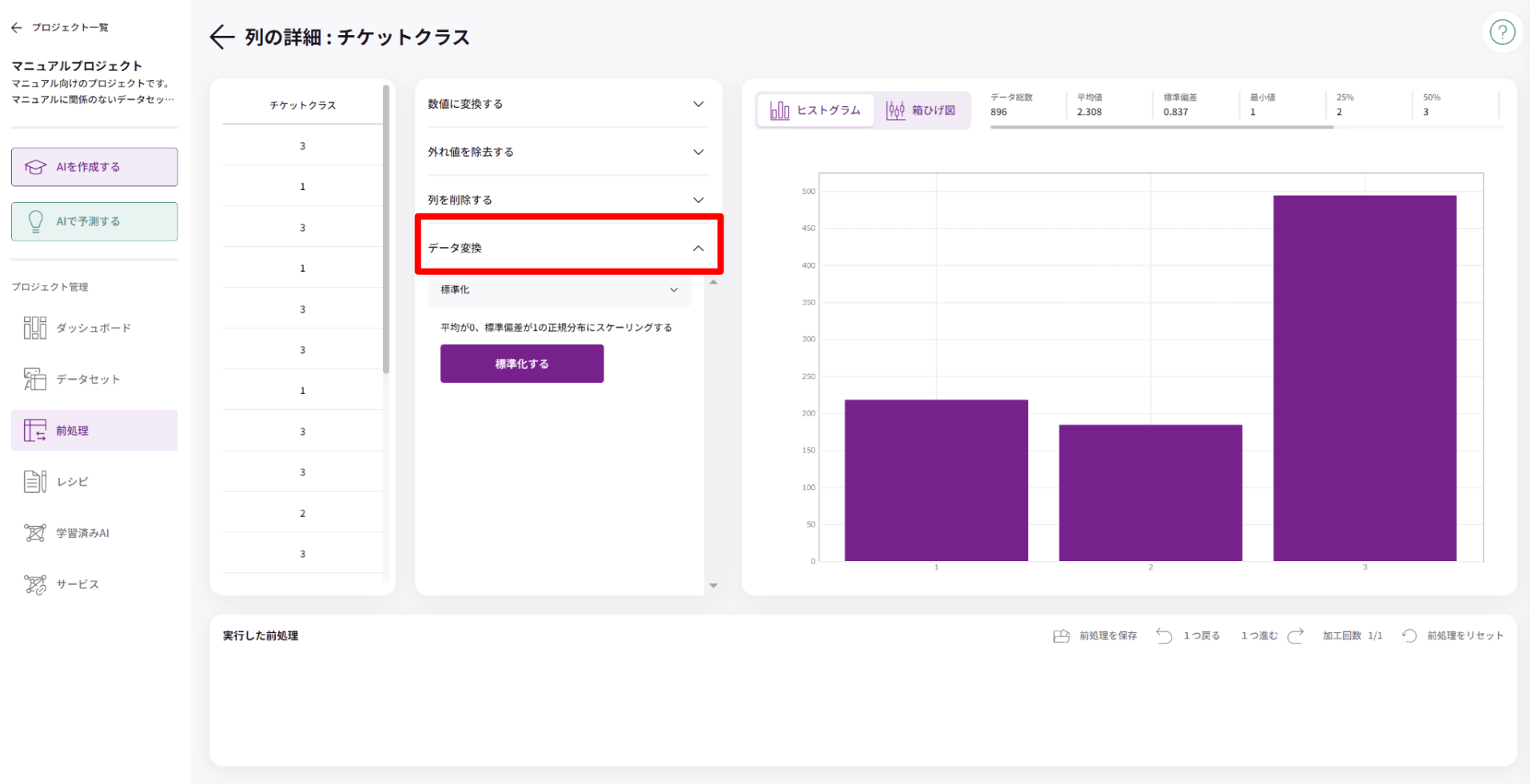
データの値を特定の範囲に変換する前処理方法です。正規化や標準化などの前処理を行います。
■標準化

標準化は、データを「平均0、標準偏差1」に変換する方法です。これを使うと、異なる特徴量(例えば身長や体重、年収など)が同じスケールで比較できるようになります。
たとえば、あるテストの得点が「数学:0~100点」なのに、もう一つのテストが「英語:0~200点」だと、単純に比較できません。
そこで「標準化」を使うと、どちらのテストも「平均を0、ばらつきを1」に揃えることができます。こうすることで、どちらの特徴量も平等に扱うことができ、機械学習モデルがバイアスなくデータを扱えるようになります。
「公平な学習」に期待できます。
■対数変換

対数変換は、データの「大きさの差」を小さくして扱いやすくする方法です。値が大きく離れていると、データの「ばらつき」が大きすぎて、分析や機械学習モデルがうまく学習できないことがあります。
そこで「対数変換」を使うと、値のスケールを縮めて扱いやすくします。
「ばらつきを抑える」「直感的な解釈がしやすくなる」「分布を正規分布に近づける」に期待できます。
■離散化
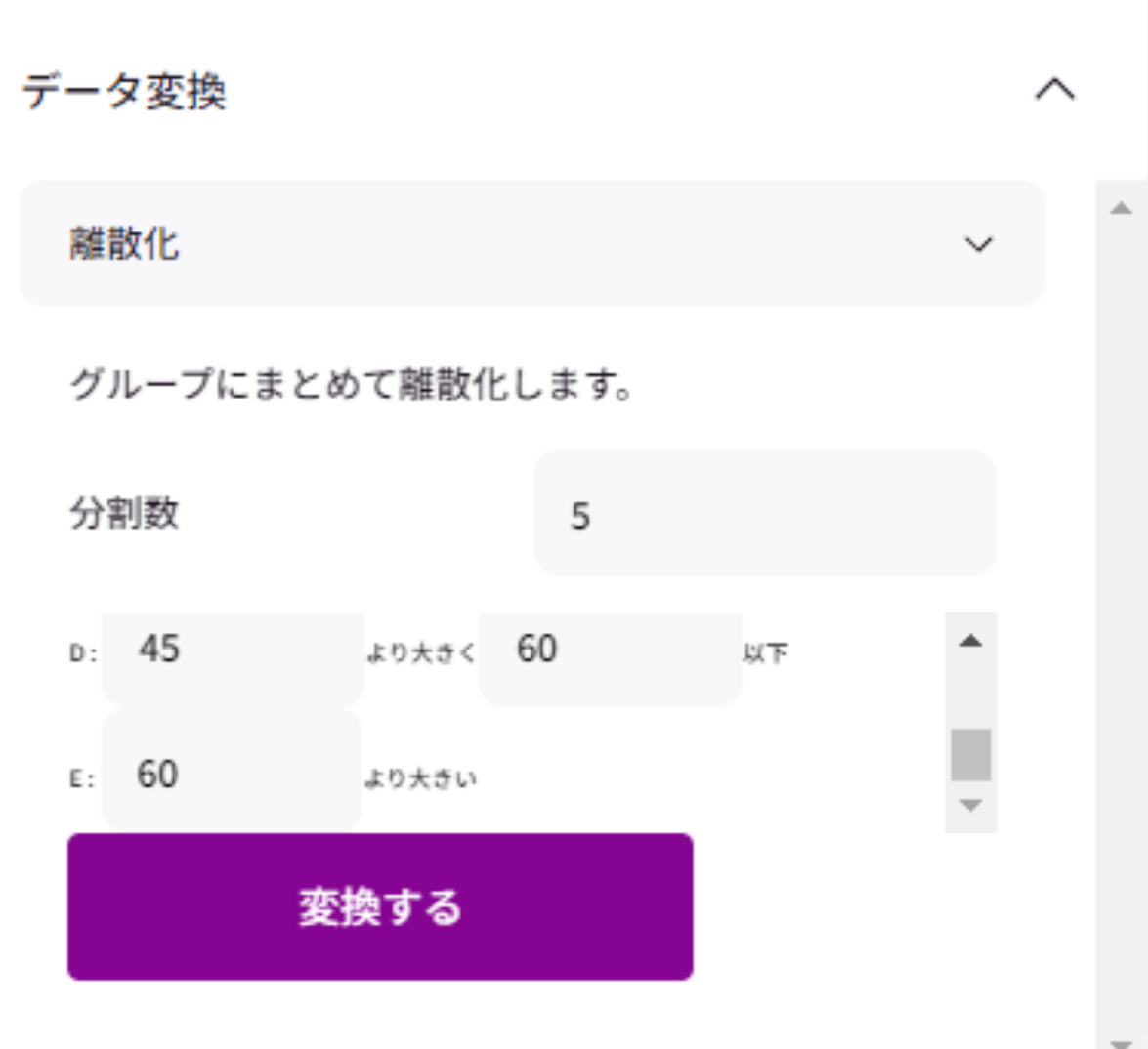

離散化は、連続的なデータを「グループ」に分けて扱いやすくする方法です。年齢を考えてみましょう。
年齢は 0歳、1歳、2歳…と細かく続きますが、分析するときに一人ひとりの細かい年齢をそのまま使うのは大変です。
そこで、年齢を「グループ」に分けることができます。
0~18歳 → 子供(A)
19~30歳 → 大人1(B)
31~45歳 → 大人2(C)
46~59歳 → 大人3(D)
60歳以上 → シニア(E)
「データの簡素化」「ノイズを減らす」「モデルの解釈がしやすい」に期待できます。