このセクションの他の記事
- 学習とは
- AIの学習設定
- 学習の詳細設定
- 学習の実行と進捗・学習の中止
- AIの学習の終了
- 概要
- 期待される効果
- 精度評価
- 精度評価の値について
- 精度評価の見方(分類・回帰)
- 精度評価の見方(文書データ(自然言語処理))
- 精度評価の見方(画像データ(ディープラーニング))
- 精度評価の見方(時系列解析)
- テスト結果の見方(数値)
- テスト結果の見方(ファインチューニング)
- 重要度
- RAGプロンプト管理機能
- テキストマイニング
- クラスタリング
- 学習情報
- 最適化の条件設定
- 最適化の式での条件設定
- 最適化結果の見方
- 最適化の仕組み
- 他のAIを確認する
- 再学習
- 学習済みAIの保存
- AIの作成お疲れさまでした!
クラスタリングの使い方
クラスタリングとは、データを類似性に基づいてグループ(クラスタ)に分割する手法です。各クラスタ内のデータは互いに類似しており、異なるクラスタのデータとは異なっていることを目的とします。クラスタリングは、機械学習やデータ分析において広く利用されています。
ClusterFlowを用いることで、クラスタリングの学習が行えます。
■使い方
使い方の説明用に、プロジェクトテンプレート「センサーデータによる異常検知」の改変したデータセット使って、MatrixFlowのクラスタリング機能を紹介します。

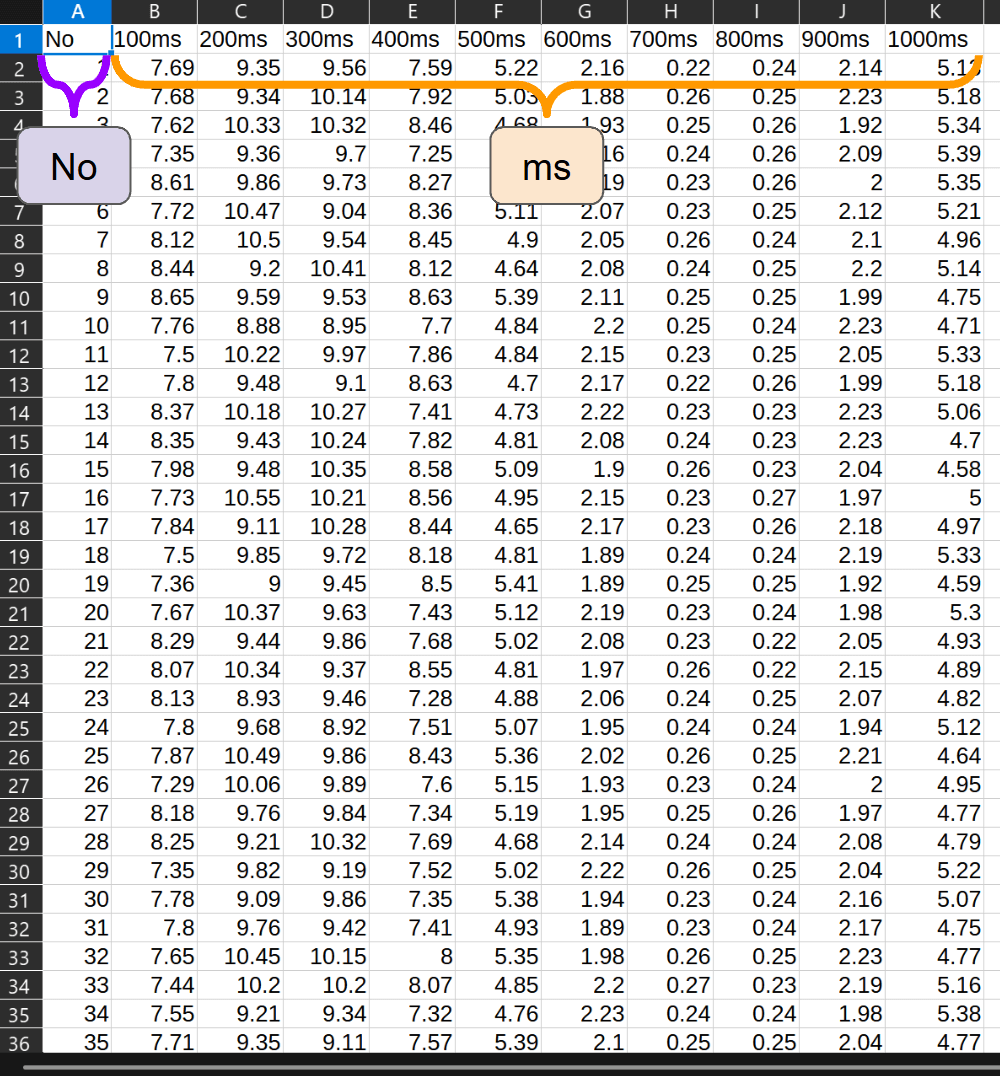
【データセット概要】
本データセットは、1000msを1周期とする波形データを、100msごとに数値化したデモ用データです。
このデータセットは以下の列で構成されています。
No:各レコードを識別するための一意の連番
ms列(10列):各時刻における波形の数値データ – 100ms、200ms、300ms、400ms、500ms、600ms、700ms、800ms、900ms、1000ms
各レコードには、1周期分(1000ms)の波形データが100ms刻みで記録されています。
波形は、1~100行が「正常な波形」、101~125行が「正常と違う波形」の想定で作られています。
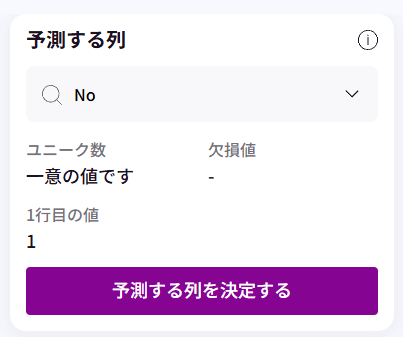
【予測する列(目的変数の設定)について】
ClusterFlow(クラスタリング)は「教師なし学習」に分類される手法のため、学習時に予測する列(目的変数)は使用しません。
そのため、予測する列には**「各レコードを識別するための一意の連番」**を指定しても問題ありません。
今回のデモデータセットでは、「No」列がこの役割を担います。
学習には影響しないため、識別用としてそのままご利用いただけます。
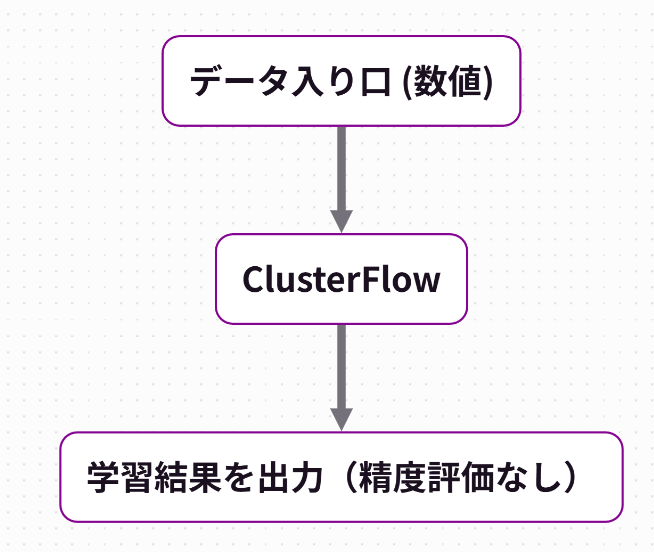
【ClusterFlowのレシピについて】
レシピの構成は右図の通りです。
終点は「学習結果を出力(精度評価なし)」を配置する必要があります。
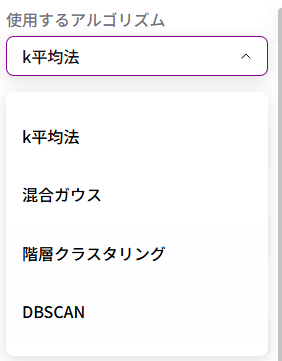
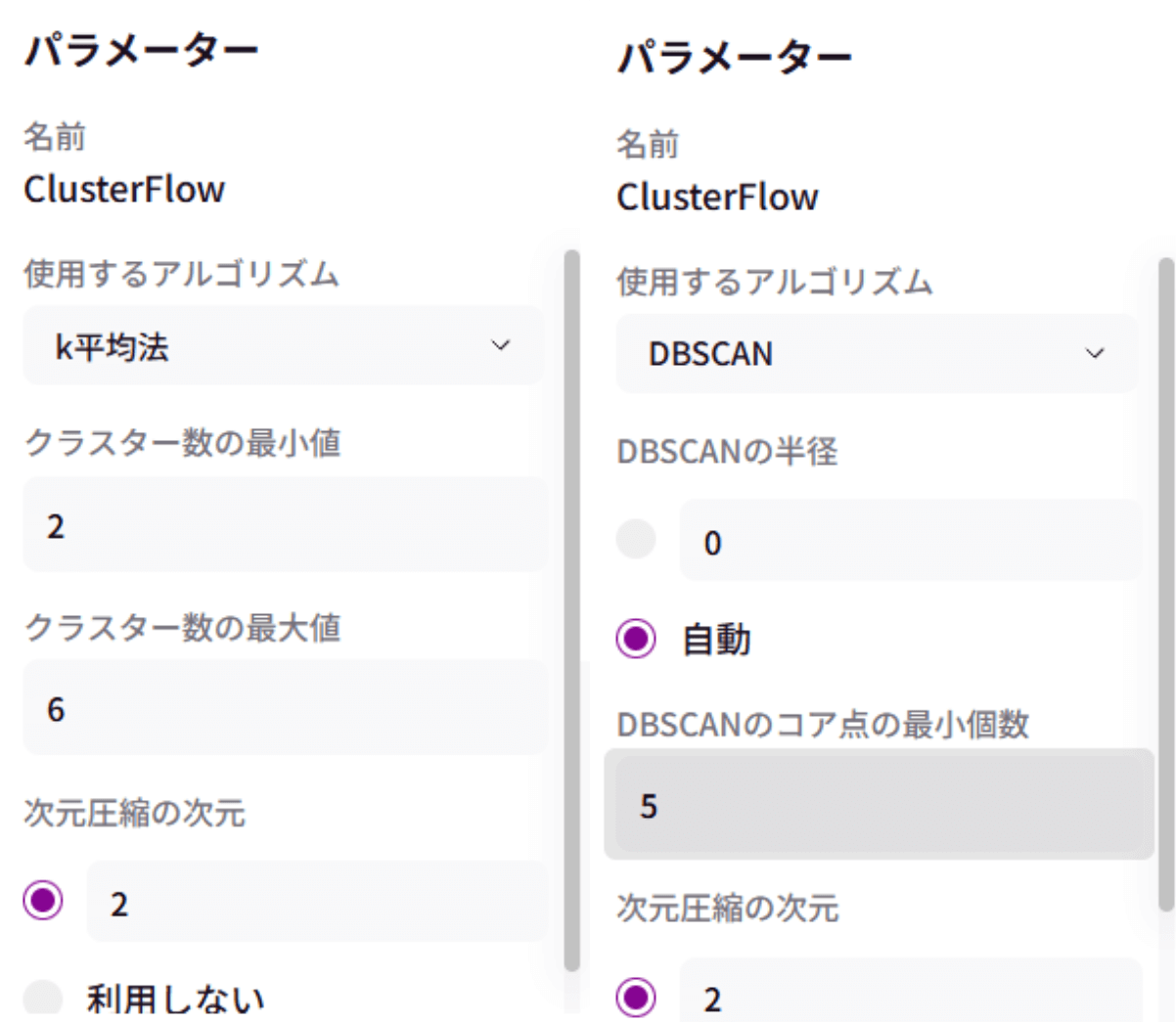
アルゴリズムは「k平均法」「混合ガウス」「階層クラスタリング」「DBSCAN」の4つに対応しています。
<k平均法 / 混合ガウス / 階層クラスタリング>のパラメータ
クラスター数の最小値※1 / クラスター数の最大値 / 次元圧縮の次元※2
※1)似たもの同士のグループの最小個数を決めます。最大値はその逆です。
※2)情報(特徴量)の意味を保ちながら少ない情報にまとめてくれます。例えば、次元を2にすると、2つの次元に纏めます。
<DBSCAN>のパラメータ
DBSCANの半径 / DBSCANのコア点の最小個数※3
※3)DBSCANの半径 / DBSCANのコア点の最小個数がわからない場合は「自動」がおすすめです。
【k平均法/混合ガウス/階層クラスタリング】
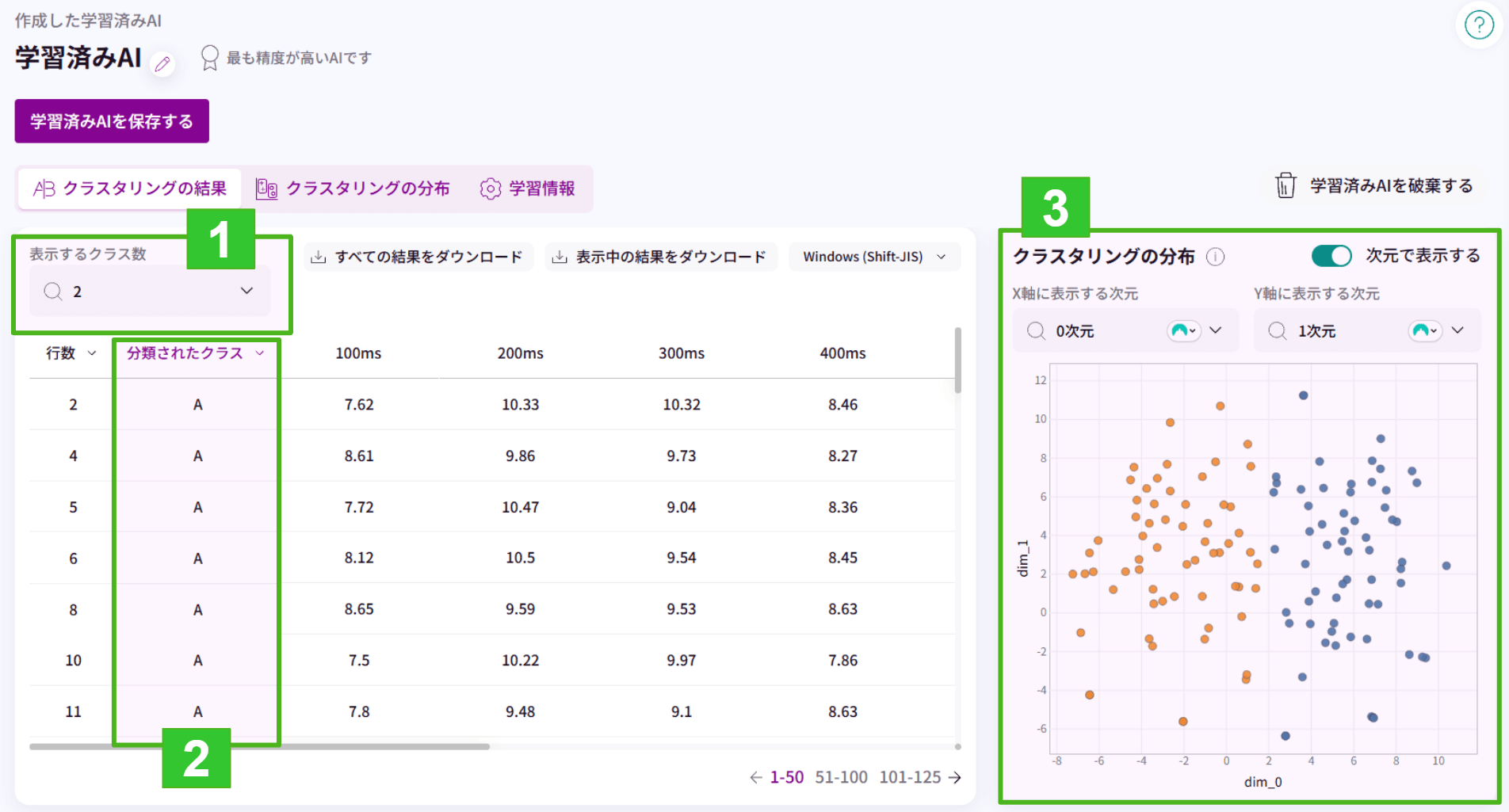
1.表示するクラス数を変更することができます。
2.表示するクラス数に合わせた「分類されたクラス」が表示されます。(アルファベットで表記されます)
3.クラスタリングの分布が表示されます。(X軸とY軸に列の設定が必要です)
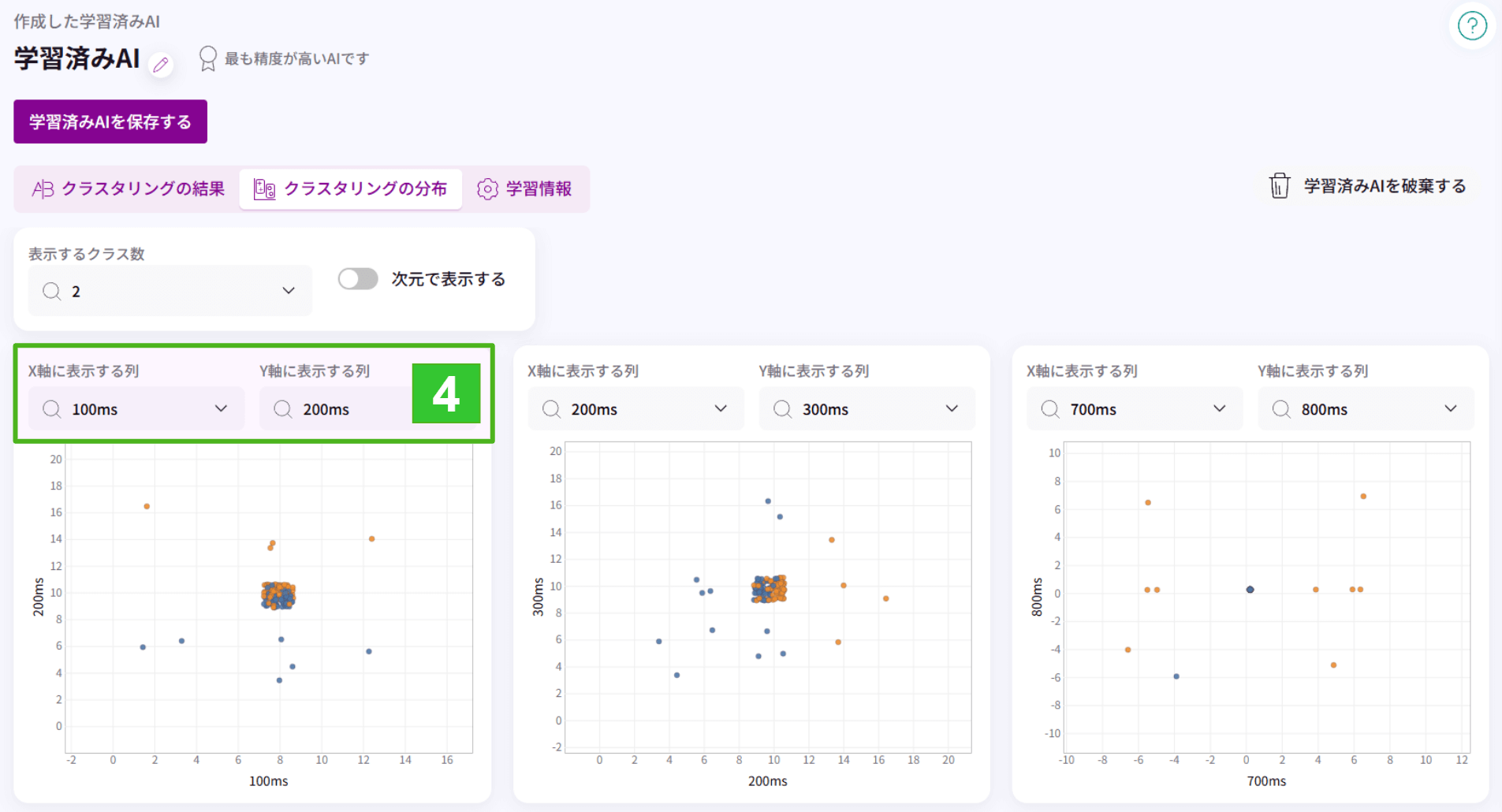
4.クラスタリングの分布のみのタブで、クラスタリングの分布のみを表示する画面です。X軸に表示する列とY軸の表示する列を設定することで、クラスタリングの分布図が表示されます。
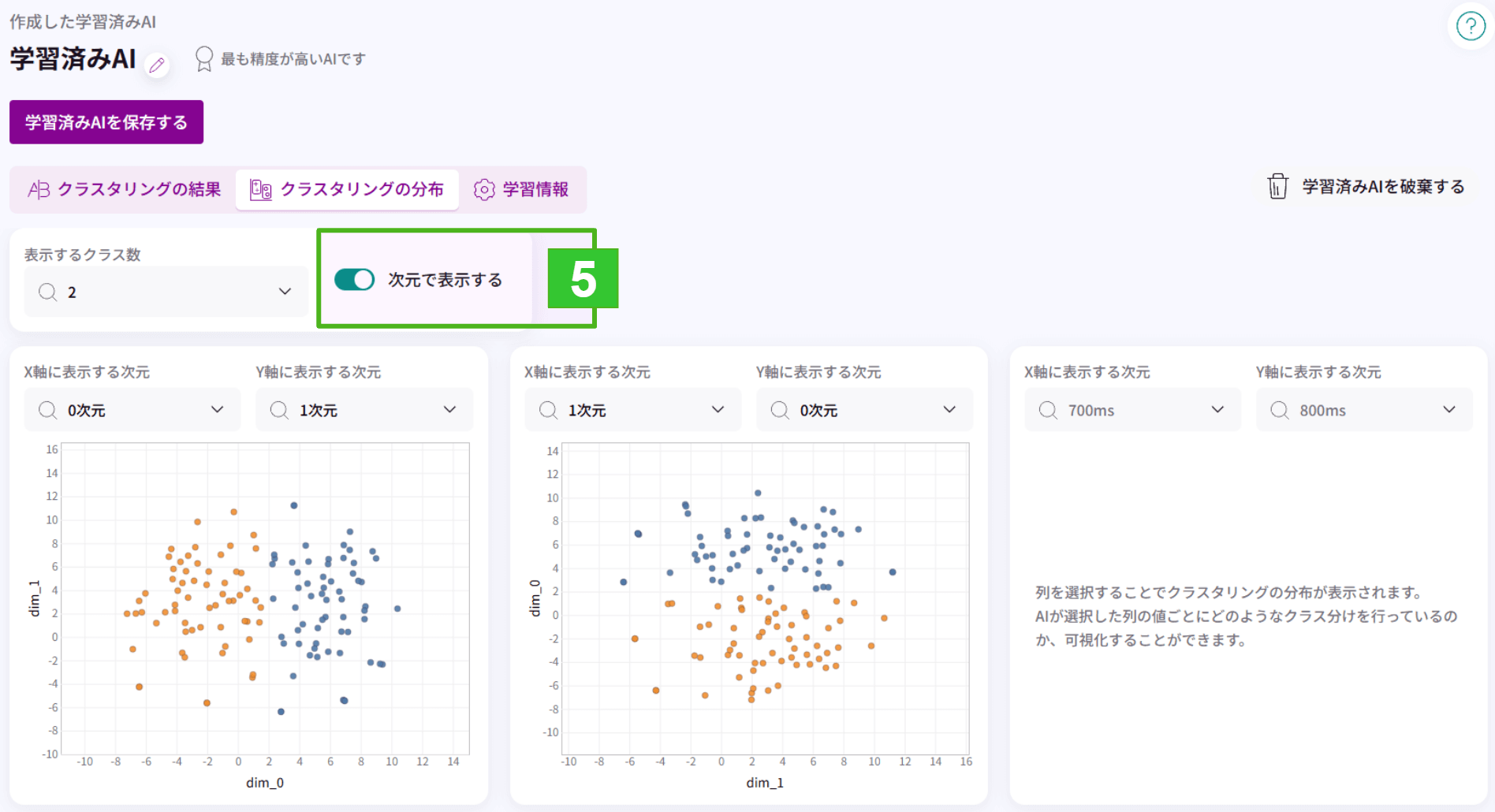
5.次元で分布を表示することができます。
【DBSCAN】
基本的な操作・使い方は【k平均法/混合ガウス/階層クラスタリング】と変わりません。
仕組みが大きく違うため、表示される内容に違いがあります。
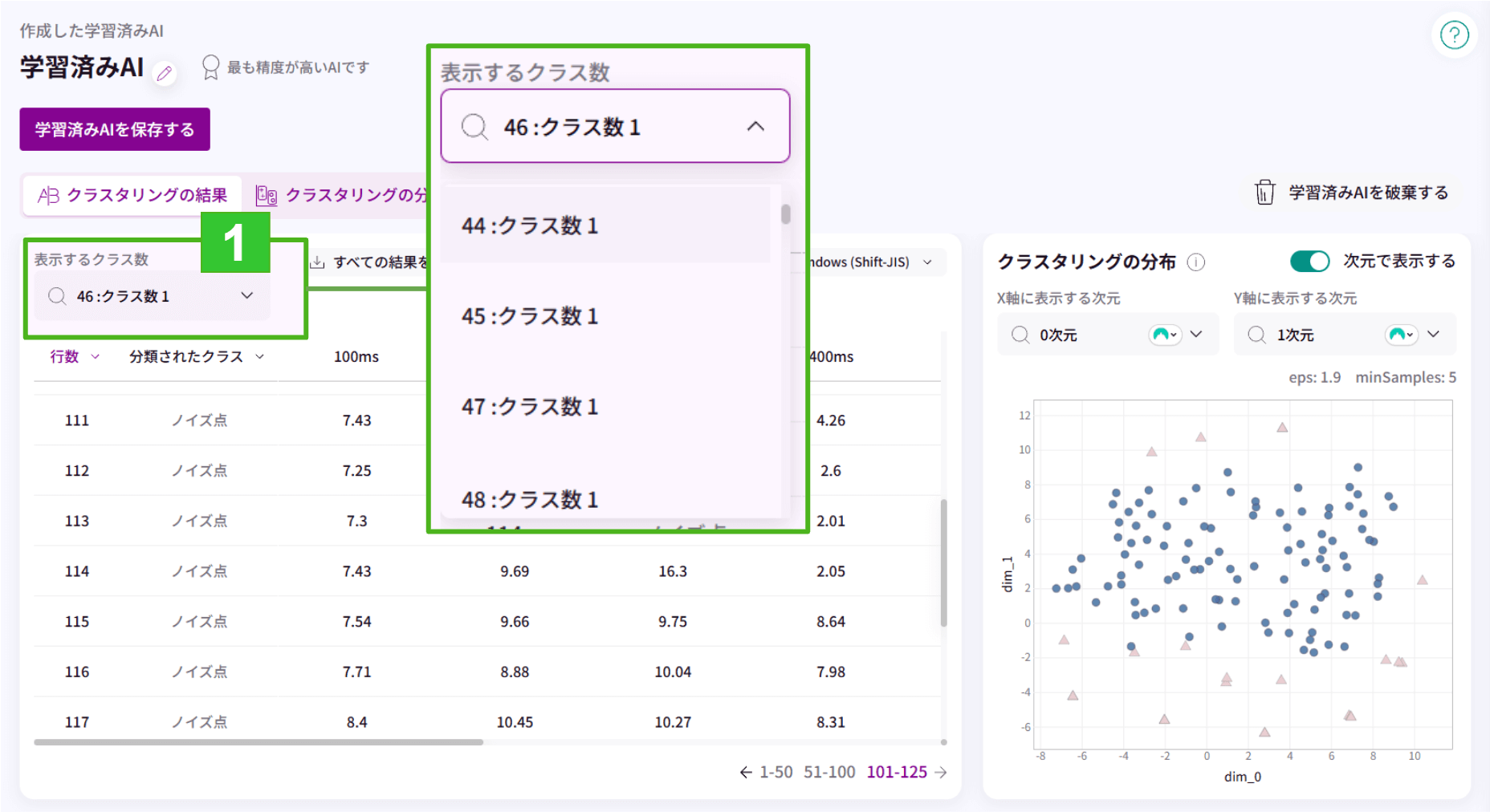
1.「表示するクラス数」で、それぞれの探索内容を選択して調節し、表示することができます。
※DBSCANの半径 / DBSCANのコア点の最小個数を「自動」にした場合
ノイズと思われる箇所がノイズ点となるように調整します。
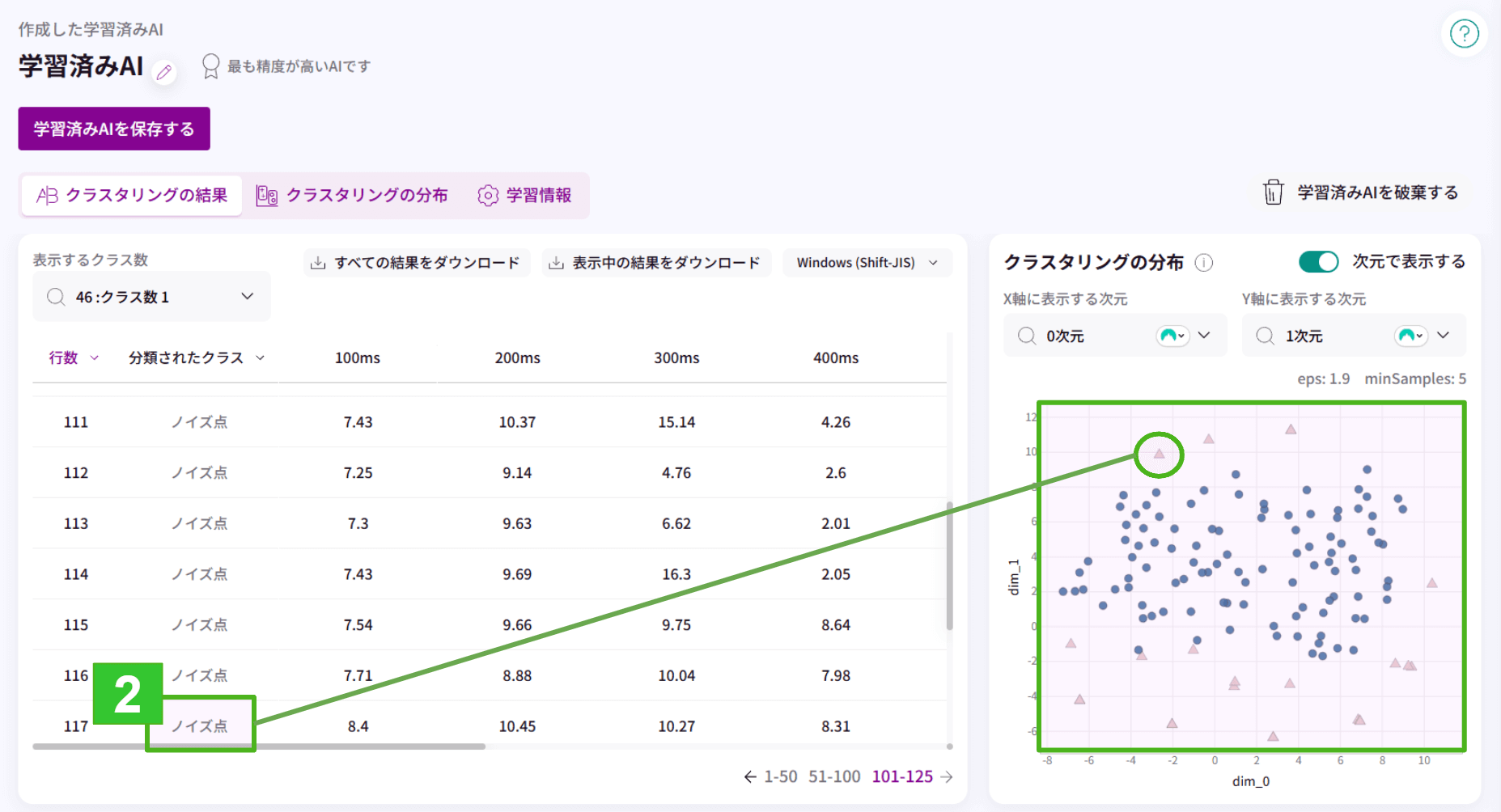
2.今回のデータセットでは100行~125行が異常値であるだろうと想定しているため、そこにノイズ点を調整しました。
ノイズ点=特定の点(今回の場合、異常値)として扱うことができます。