このセクションの他の記事
精度評価の見方(分類・回帰)
◆分類
分類では、次の評価指標を用いてAIモデルの精度を評価します。
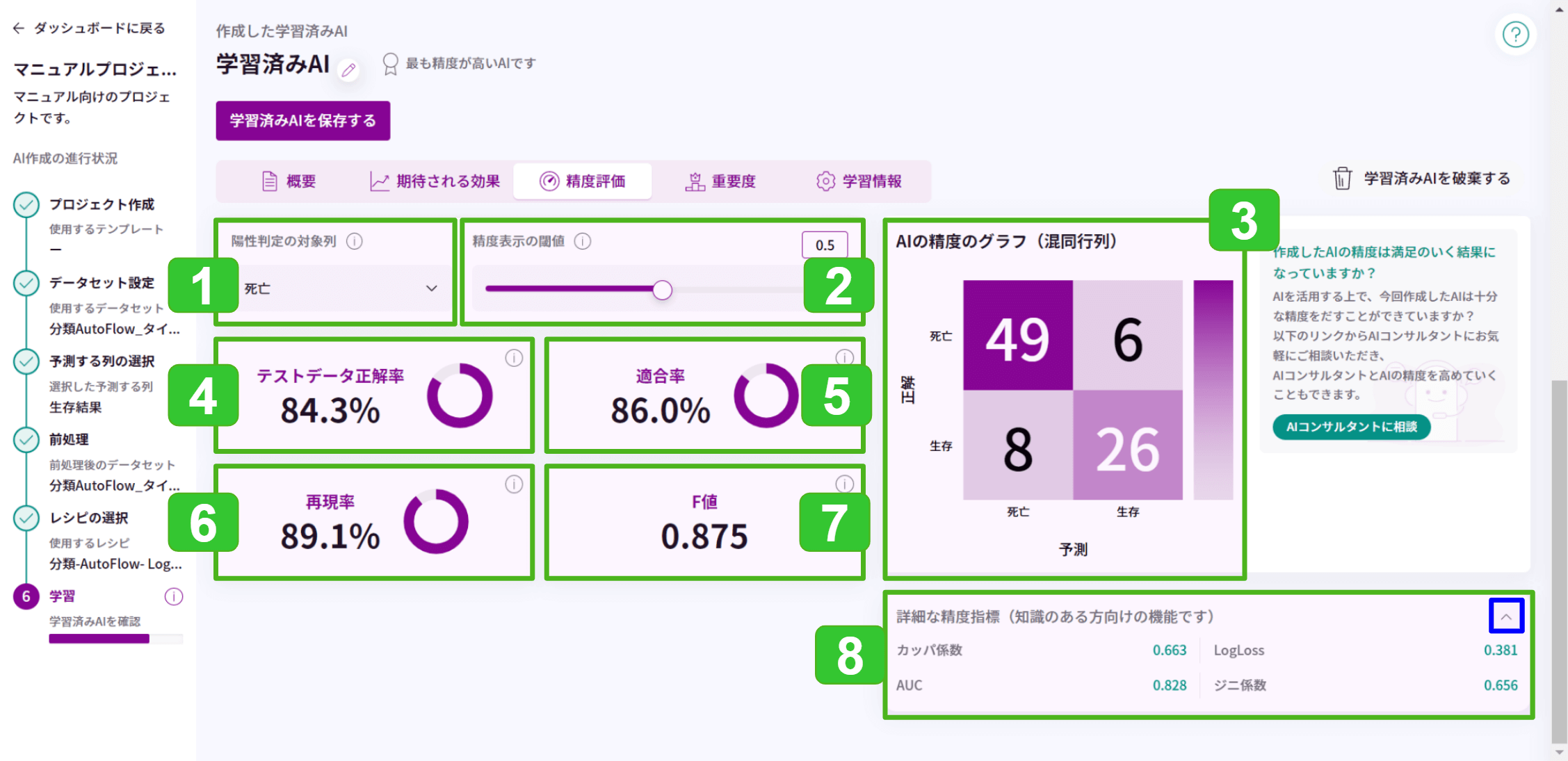
1.陽性判定の対象列
2値分類の場合のみどちらの列を基準に(陽性として)精度評価値を計算するか選択できます。
影響する精度評価値は「適合率」「再現率」「F値」の3つです。精度評価値については、後述をご覧ください。
2.精度表示の閾値
一部のアルゴリズムのみ調整できます。
AIモデルの予測精度を判断するのに使う「精度評価値」を計算する閾値を調整できます。デフォルトは「0.5」です。
この閾値は、予測結果を真と判定するか偽と判定するか区切りとなる値です。閾値を変更すると精度評価値が再計算され、混同行列も変化します。
特に適合率と再現率、どちらかをより重要視したいモデルの場合、試算することで最適な閾値を求めることができ、推論時に閾値を指定することで、より精度よく予測が行えるようになります。
3.混同行列(Confusion Matrix)
分類した予測結果をまとめた表です。
どのカテゴリーを正しく分類でき、どのカテゴリーを誤って分類したか確認できます。
真を0、偽を1としたとき、
・正解データ 0、AIの予測 0(予測アタリ)
True Positive:47個
・正解データ 1、AIの予測 0(予測ハズレ)
False Positive:12個
・正解データ 1、AIの予測 1(予測アタリ)
True Negative:23個
・正解データ 0、AIの予測 1(予測ハズレ)
False Negative:8個
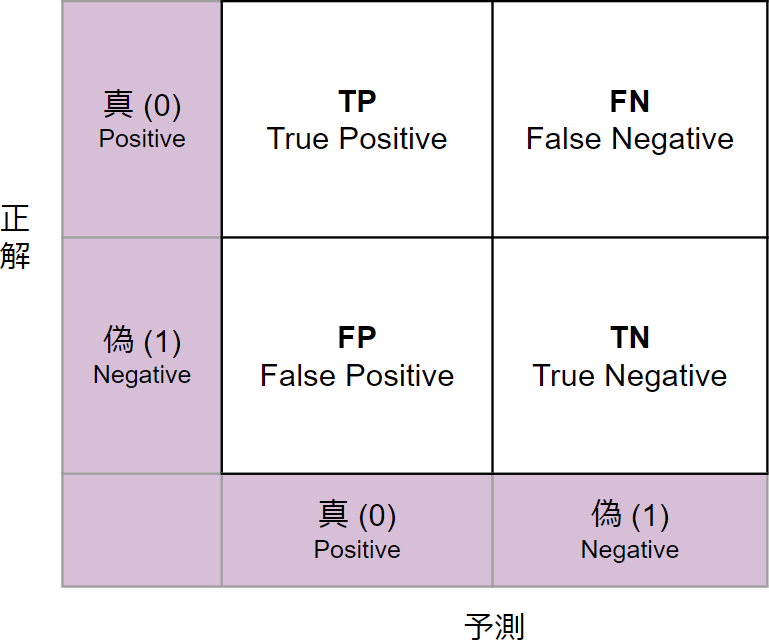
<混同行列の色の濃さについて>
正解とAIの予測が一致している個数が多いほど、濃い紫で表示されます。
予測があたっている部分の色が濃ければ、AIモデルの予測精度は高いと言えます。
逆に、予測がハズレている部分の色が濃ければ、予測精度は低いと言えます。
4.テストデータ正解率(accuracy)
すべての予測結果の内、実際の値(=投入した学習データの値)と一致しているのがどのくらいあるかを表す、AIモデルを評価する指標です。
100%に近いほど予測精度が良いことを表します。
MatrixFlowでは、学習データセットの一部を予測精度を評価するためのテストデータとして使い、AIモデルが予測した結果とテストデータ内の実際の値を比較して正解率を導き出しています。そのため「テストデータ正解率」と表示しています。
(47+23)/(47+12+8+23)
=0.777=77.8%
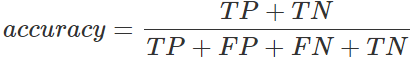
5.適合率(precision)
AIが真と予測したものの中で、実際の値も真であったものの割合です。
予測が実際の値と、どのくらい一致しているかを表す「正確性」の指標です。
100%に近いほど正確に予測できていることを表します。
(47)/(47+12)
=0.7966=79.7%
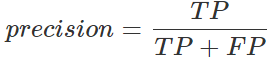
6.再現率(recall)
実際の値が真のものの中で、AIが真と予測したものの割合です。
予測が実際の値を、どのくらい網羅しているかを表す「網羅性」の指標です。
100%に近いほど網羅的に予測できていることを表します。
(47)/(47+8)
=0.8545=85.5%
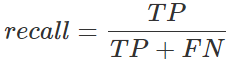
<適合率と再現率について>
適合率と再現率はトレードオフの関係にあります。
ここでいうトレードオフとは、適合率を上げようとすると再現率が下がり、再現率を上げようとすると適合率が下がるという、両立できない関係性ということです。
どのような値を予測したいのか、データの性質を明確にしておかないと誤ったAIモデルを作成してしまう恐れがあるので注意しましょう。
例)ある病院でがん検診を行い、陽性/陰性の診断をしました。
この時、厳しめに診断し陽性結果を多く出したとします。
この中には実は陰性のケースも含まれますが、真に陽性の的中率が上がるため、再現率は高いです。
しかし、少しでもがんの兆候が見られれば陽性と判断したため、適合率は低いです。
逆に、甘めに診断し陰性結果を多く出したとします。
一般的に陰性のほうが多いため、適合率は高いです。
しかし、がんの兆候がわずかにある場合も陰性と判断しているため、再現率は低いです。
このようながん検診のケースでは、がんの発見を見逃さないようにするため、網羅性を表す[再現率]を重視するのが良いでしょう。
7.F値(F-measure)
「正確性の適合率」と「網羅性の再現率」を組み合わせた指標で、調和平均です。
1.0に近いほど予測精度が良いことを表します。
2*(0.7966×0.8545)/(0.7966+0.8545)
=0.825
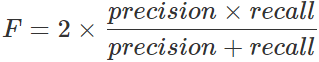
8.詳細な精度指標
AIや統計の知識がある方向けに、より詳しい精度指標の値を表示します。
アルゴリズムによって、表示されない指標もあります。
ここに表示される指標については本マニュアルでは解説しません。
詳細は書籍やWebサイトなどでお調べいただくか、「AI構築サポート(オプション)」をご契約の場合は弊社サポートにお問い合わせください。
◆回帰
回帰では、次の評価指標を用いてAIモデルの精度を評価します。
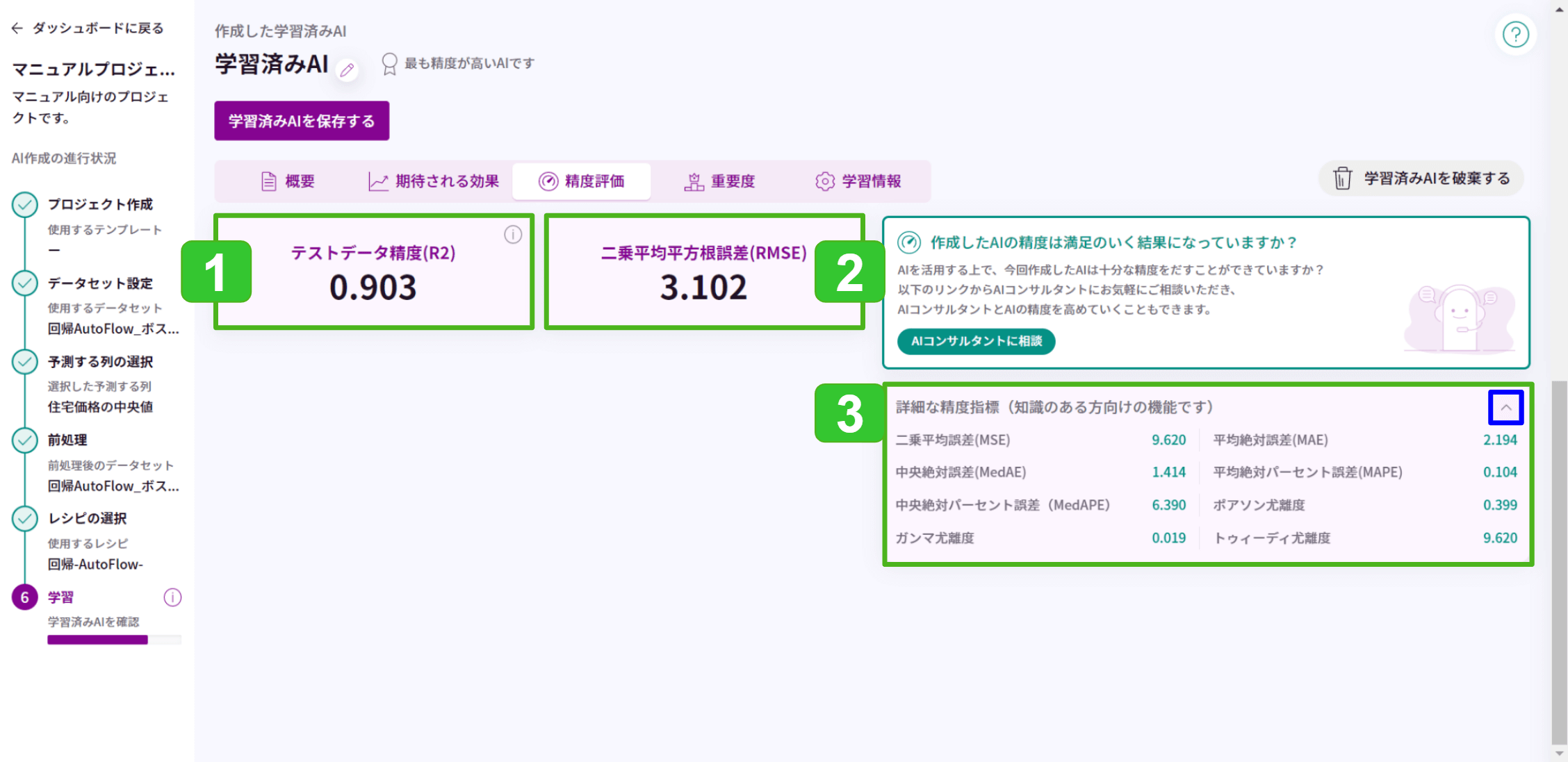
1.テストデータ精度(R2)
AIが予測した値が実際の値にどのくらいあてはまるかを示す指標です。
予測値と実際の値の誤差が大きいほど値は0.0に近くなり、誤差が小さいほど値は1.0に近づきます。そのため、1.0に近いほど予測精度が高いと言えます。
通常は0.0~1.0(=0%~100%)の値を取りますが、1から減算して精度を求めるため、データによってはマイナスになることもあります。
2.二乗平均平方根誤差(RMSE)
精度(R2)と同じく、AIが予測した値が実際の値にどのくらいあてはまるかを示す指標ですが、計算方法が異なります。
実際の値と予測値の誤差が小さいほど値は小さく、0.0に近いほど予測精度が高いと言えます。
RMSEは Root Mean Squared Error の略で、全データの実際の値と予測値の「誤差の2乗の平均を求めて平方根を取った値」です。
RMSEは計算の際に実際の値と予測値との誤差を2乗しているため、双方の値が離れるほど指数関数的に増えます。つまり、外れ値の影響を受けやすいということです。R2が外れ値の影響を受けているかの指標になります。
3.詳細な精度指標
AIや統計の知識がある方向けに、より詳しい精度指標の値を表示します。
アルゴリズムによって、表示されない指標もあります。
ここに表示される指標については本マニュアルでは解説しません。
詳細は書籍やWebサイトなどでお調べいただくか、「AI構築サポート(オプション)」をご契約の場合は弊社サポートにお問い合わせください。