このセクションの他の記事
推論結果の見方(文書データ(zip, txt, pdf)の分類、ベクトル化)
文章や単語などの文書データの場合、投入するデータのファイル形式がCSVファイルとZIPファイルではレシピの構成が異なるため、結果の表示形式も異なります。
ここでは、TXTファイルまたはPDFファイル形式の文書データをZIPファイルに圧縮して投入し、分類問題、またはベクトル化の予測を行ったとき、画面に表示される結果について解説します。
データセット(ZIPファイル)にはフォルダ構造のルールがありますので、詳しくは 推論用データセットの作り方 をご覧ください。
なお、CSVファイル形式文書データを投入する場合の推論結果は、数値データの分類と同様です。
<参考:レシピの違い>
・CSVファイル:「特定列への処理」ブロックを使い、文章や単語の列を分かち書きするなど、自然言語処理を行う流れに分岐します。推論の種類は「分類」しか選択できません。
・ZIP, TXT, PDFファイル:投入データすべてを自然言語処理するので、処理を分岐しません。推論の種類は「分類」と「ベクトル化」を選択できます。
■分類
推論に投入したZIPファイルをシステム内で解凍し、個々の文書ファイルごとに予測を行います。
文書txtファイルを1ファイルのみ投入して、予測することも可能です。ただし、PDFは1ファイルでの推論に対応していません。
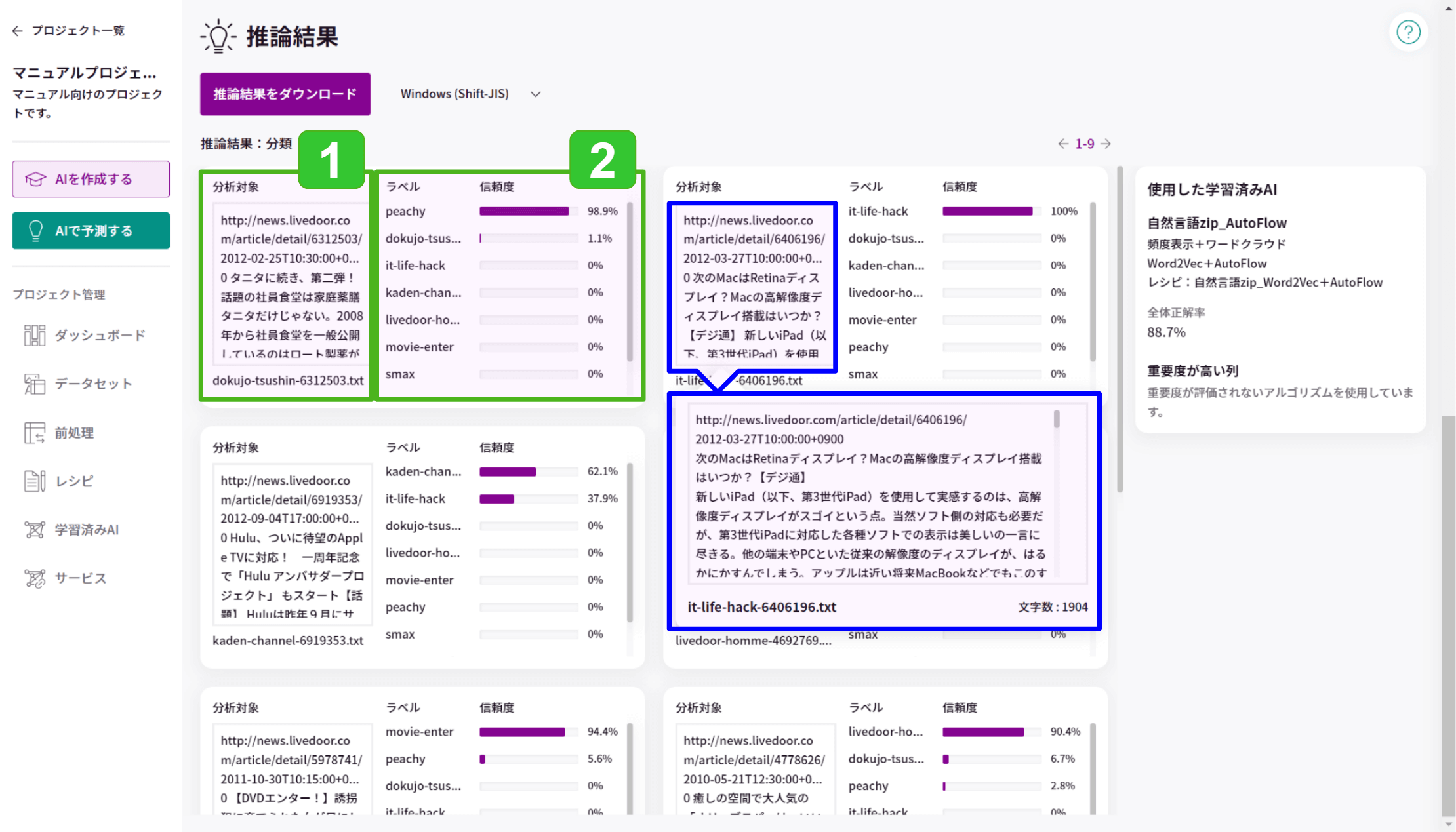
- 分析対象の.txt, .pdfファイルの内容です。
文書ファイルごとに冒頭のみ表示され、クリックすると全文を確認できます。(参考:上図青枠) - 属する可能性が高いと予測した分類クラス(グループ)順に表示します。
信頼度が高いほど、その分類クラスに属する可能性が高いことを表します。
上図の場合、peachy に属する可能性が98.9%、dokujo-tsushin に属する可能性が1.1%と判定されたことが分かります。
■ベクトル化
投入したデータセット内で、分析対象に類似している文書データを予測します。
投入したデータセット内で似ている文書を探すため、文書ファイルを1ファイルのみ投入してベクトル化を行うことはできません。
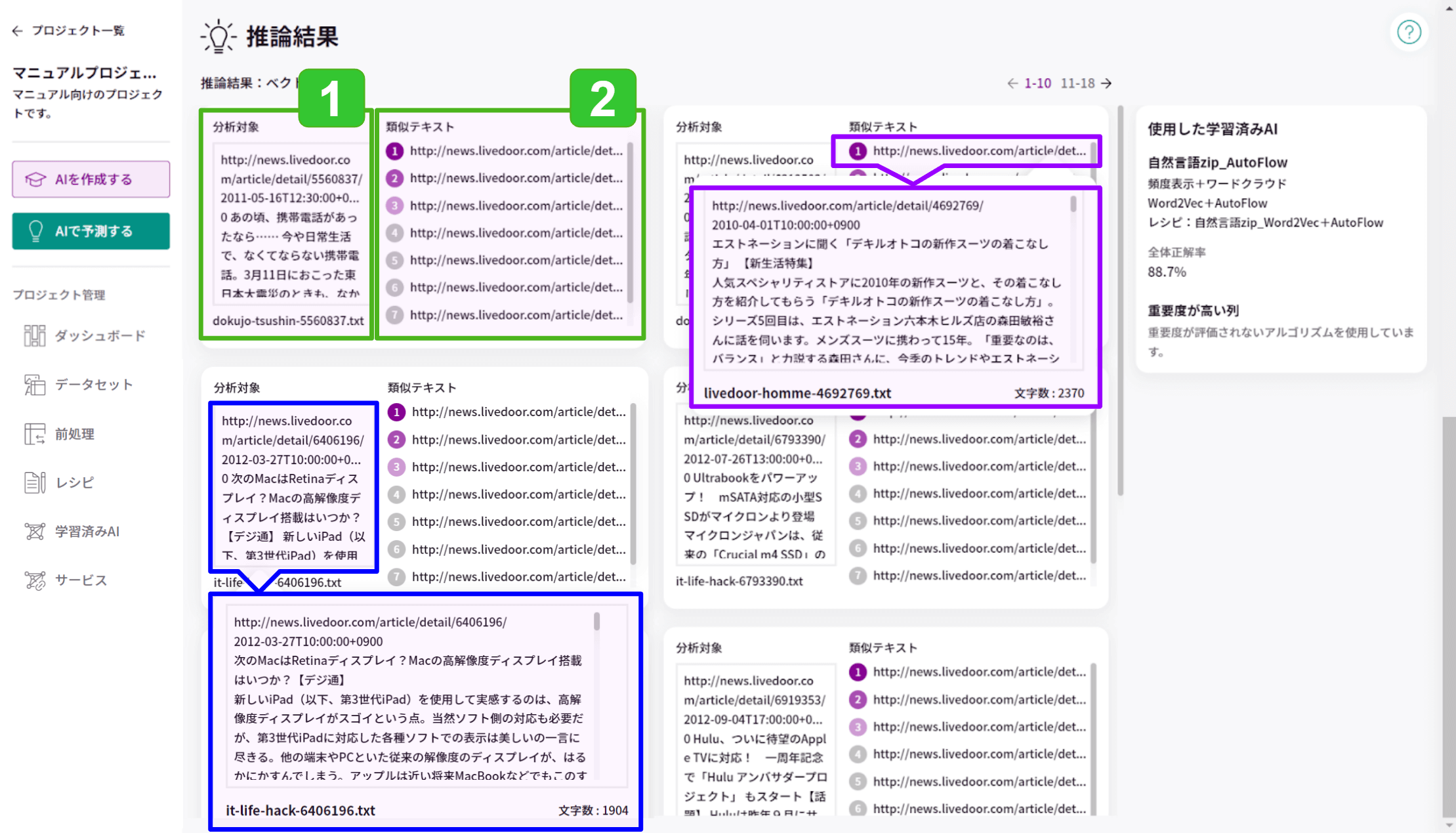
- 分析対象の.txt, .pdfファイルの内容です。
文書ファイルごとに冒頭のみ表示され、クリックすると全文を確認できます。(参考:上図青枠) - 投入したデータセット内で、分析対象に類似していると予測した上位8ファイルの内容です。
ファイルごとに冒頭のみ表示され、クリックすると全文とファイル名を確認できます。(参考:上図紫枠)
■推論結果のダウンロード
推論結果は、分類問題を予測したときのみ、CSVファイル形式でダウンロードすることができます。また、文字コードもShift-JISとUTF-8から選択可能です。
ダウンロード方法は、推論結果のダウンロード をご覧ください。
■ダウンロードファイルに出力される項目
<文書データ(zip, txt, pdf)の分類>
ベクトル化の結果はダウンロードできません。
| 項目 | 列名 | 説明 |
|---|---|---|
| TXT/PDFファイル名 | filename | ZIPファイルを内部で解凍して取り出した、分析対象の個々のTXTまたはPDFファイル名 |
| TXT/PDFファイルの内容 | body | |
| 予測結果 | label | |
| 各分類クラスの信頼度 | {クラス名}_probability | 分類クラスが5つなら、5列出力 |