このセクションの他の記事
推論結果の見方(数値データの分類・回帰/文書データ(csv)の分類)
数値データを投入して分類問題、または回帰問題の予測を行ったとき、画面に表示される結果について解説します。
また、CSVファイル形式の文書データの分類予測を行ったときも、同様の結果が得られます。
■推論結果
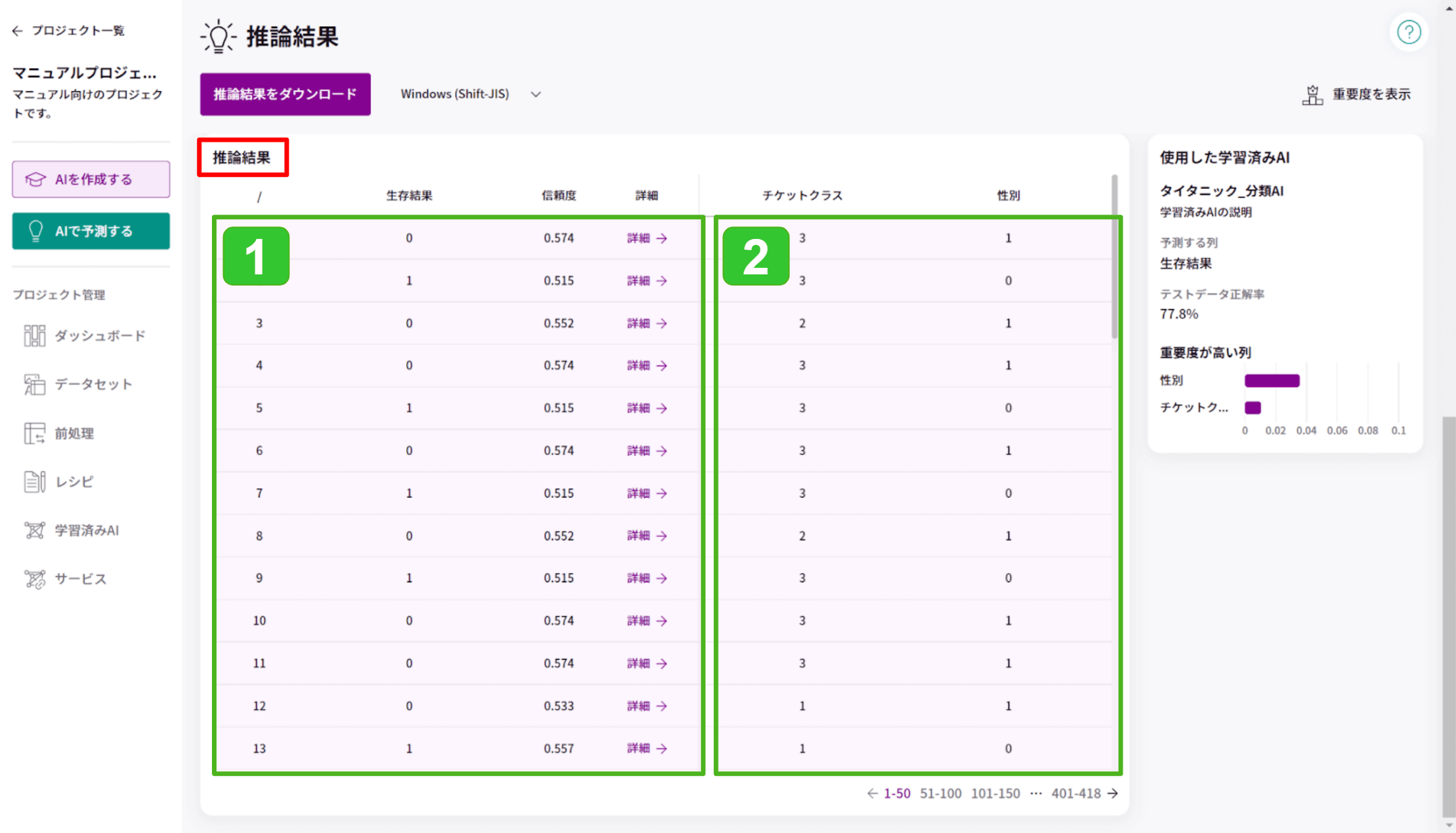
- 推論結果と推論の信頼度が行ごとに表示されます。
「詳細→」をクリックすると、その行の推論結果の詳細が確認できます。詳細は後述をご覧ください。 - 推論に使用した列の値が表示されます。
推論に使用する列は、AIモデルの学習時に指定した[学習に使用する列]です。
■推論結果の詳細
「詳細→」をクリックすると、その行の推論結果の詳細が確認できます。
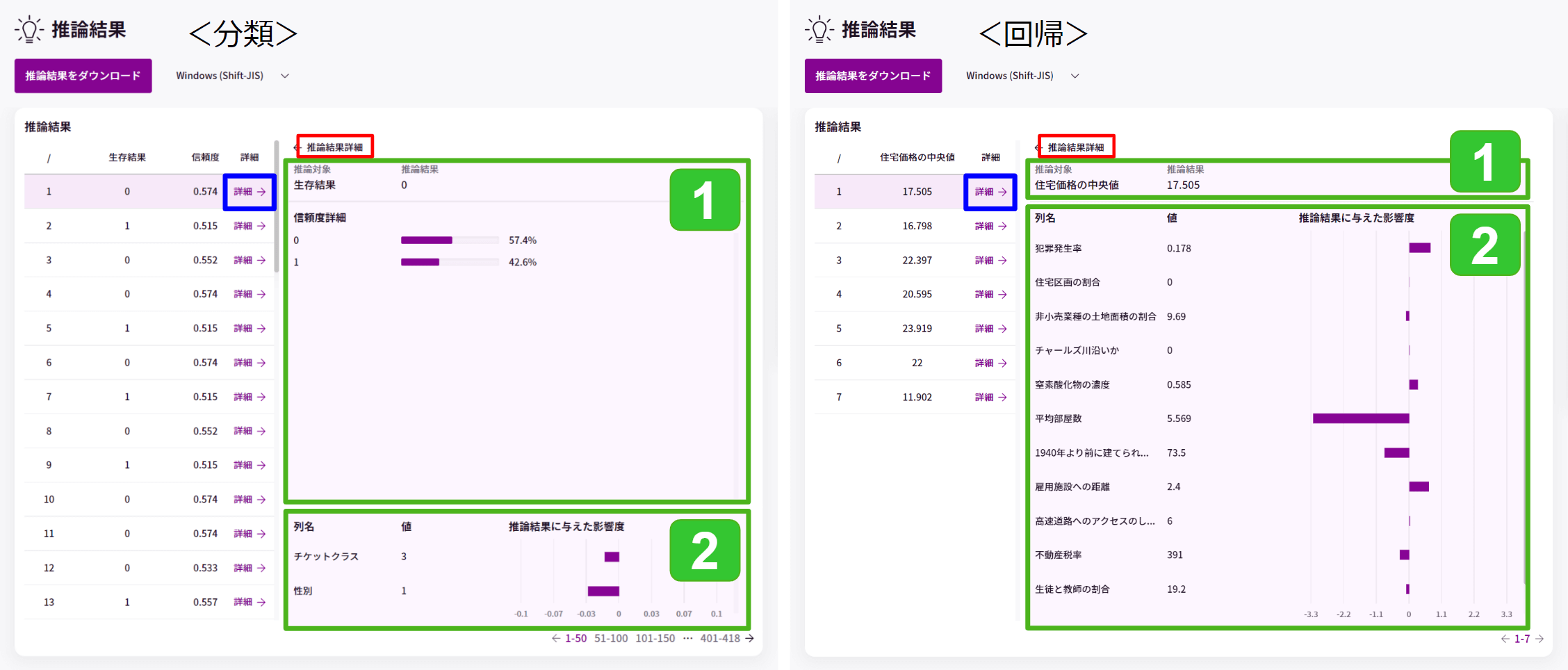
1.推論結果と、その結果の信頼度を表示します。
信頼度とは「〇と△のデータがある場合、どれだけ〇のデータらしいか」を示す情報で、そのデータが〇のクラスに属する確率を表します。
上図の場合、0 に属する可能性が57.4%、1 に属する可能性が42.6%で、推論結果は「0」と判定されたことが分かります。
※ 回帰分析の場合、信頼度は算出されません。
2.推論に使用した各列の値と、その値がどれだけ推論に影響を与えたか影響度を表示します。
前処理でOne-Hotエンコーディングやダミーコーディングを行って複数列になった列も、ここでは1列に戻して計算されます。
棒グラフにマウスカーソルを合わせると、影響度を数値(小数第4位を四捨五入)で確認できます。
※ CSVファイル形式の文書データを分類する場合は、影響度が評価されないアルゴリズムを使用しているため表示されません。
■影響度の考え方
影響度とは、推論結果が推論に使用したそれぞれの列からどのくらい影響を受けているかを表します。影響度なのでマイナス値もあり得ます。
AIモデルが列の値をどう使って予測をしたのか、列の値は予測結果にどのくらい影響を与えているのかなど、予測結果の解釈に用います。
<分類の場合>
タイタニック号のデータを例に、生存「1」死亡「0」として生死を予測します。
予測結果:0(死亡)
⇒「性別」の絶対値が「チケットクラス」よりも大きいため、性別の値が予測に大きく寄与し、
かつ、マイナス値は予測値が小さくなる方向に影響を及ぼすため、
死亡0と予測したと説明できます。
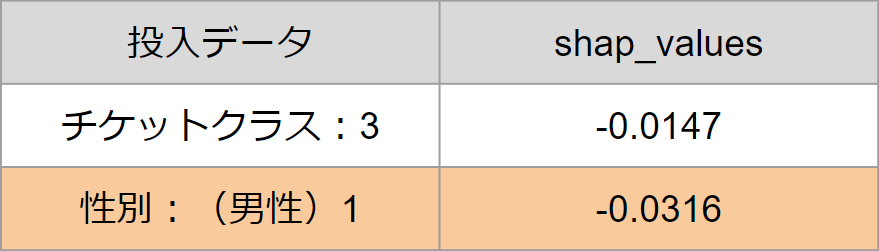
予測結果:1(生存)
⇒ 「性別」の絶対値が「チケットクラス」よりも大きいため、性別の値が予測に大きく寄与し、
かつ、プラス値は予測値が大きくなる方向に影響を及ぼすため、
生存1と予測したと説明できます。
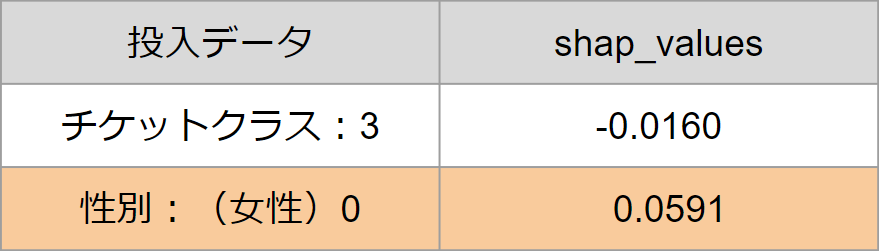
<回帰の場合>
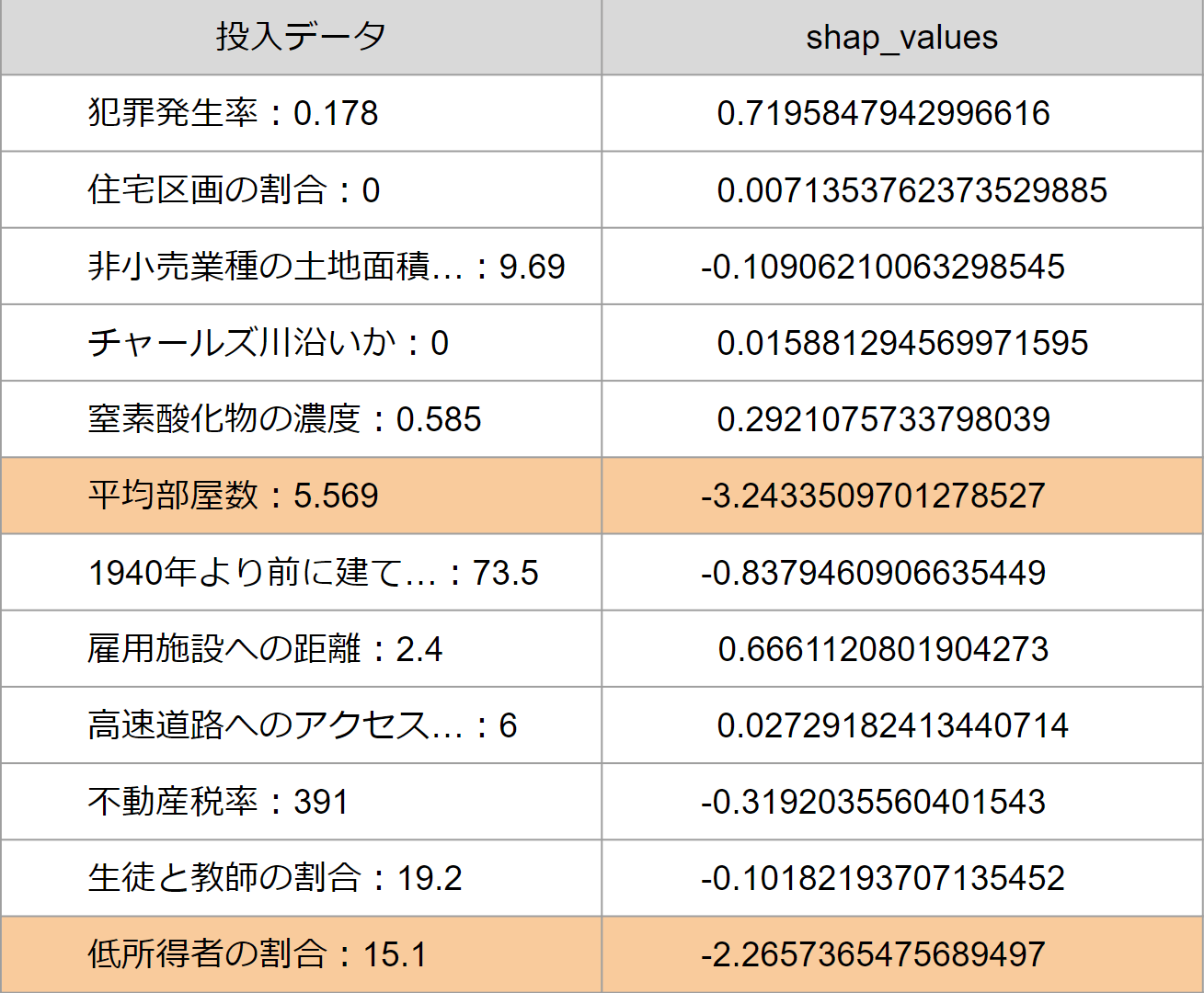
ボストン市住宅価格のデータを例に、住宅価格の中央値を予測します。
予測結果:17.505(本事例のデータセットでの平均予測値:19.302)
⇒「平均部屋数」と「低所得者の割合」の絶対値が他と比較して大きく、
かつマイナス値のため推論結果の価格を下げる方向に大きく寄与したと説明できます。
■推論結果のダウンロード
推論結果は、CSVファイル形式でダウンロードすることができます。また、文字コードもShift-JISとUTF-8から選択可能です。
ダウンロード方法は、推論結果のダウンロード をご覧ください。
■ダウンロードファイルに出力される項目
<数値データの分類・回帰>
| 項目 | 列名 | 説明 |
|---|---|---|
| 推論に投入した実データ | データセットの列名と同じ | データセット内のすべての列の値 |
| 予測結果 | データセットの列名と同じ | [予測する列名]に指定した列名 |
| 各分類クラスの信頼度 | {クラス名}_probability | 分類のときのみ出力 分類クラスが3つなら、3列出力 |
| 推論に使用した列の影響度 | {列名}_importance | 推論に使用したすべての列 |
<CSVファイル形式の文書データの分類>
| 項目 | 列名 | 説明 |
|---|---|---|
| 推論に投入した実データ | データセットの列名と同じ | データセット内のすべての列の値 |
| 予測結果 | データセットの列名と同じ | [予測する列名]に指定した列名 |
| 各分類クラスの信頼度 | {クラス名}_probability | 分類クラスが3つなら、3列出力 |
※文書データの「推論に使用した列の影響度」
数値データの分類とは異なり、推論に使用した列の影響度が評価されないアルゴリズムを使用しているため、出力されません。