自然言語処理の前処理手順をPythonコード付きでご紹介
私たちの身の回りには、SiriやAlexaに代表されるAIアシスタントや、他言語をリアルタイムで翻訳できる端末などが現れ、人が言葉で機械を簡単に操作することが当たり前の時代となってきました。 その背景として、「自然言語処理(Natural Language Processing)」と呼ばれる技術が確立しつつある点が重要です。 この記事では、自然言語処理の概要や仕組みを詳しく解説し、Pythonを活用した自然言語処理の前処理を行う方法を紹介します。

-
目次
日本語の自然言語処理で必ず必要となる前処理
Pythonを活用した、一般的な前処理の手順
プログラミング不要でAI予測モデルが構築できる「MatrixFlow」面倒なデータの前処理も簡単! -
日本語の自然言語処理で必ず必要となる前処理
私たちの身の回りには意識せずとも、さまざまな文字や言葉があふれています。
簡単に挙げると以下のようなものです。
・話し言葉
・書き言葉
・ネットスラング
・外国語
・プログラム言語
・多種多様の記号など人間は、これらの混在したテキストデータをある程度瞬時に理解できますが、機械学習などでは、それらの分類や予測・理解は容易ではありません。
そのため、いかに分類モデルにこれらを理解しやすくさせるかもしくは、人間が理解・処理しやすくするかといったことが、前処理の必要な理由です。
それでは、前処理を行うメリットを順番に見てみましょう。データ利用の容易性の向上
データ形式を揃えることは、データを利用する上で欠かせないポイントは以下です。
チーム間でのデータ利用の簡易化
バグの低減
後段処理の簡素化/高速化
データの本質の発見前処理を行うことで、データへの理解を深めることができ、さらに、本当に必要なデータを見つけ出すことができるようになってき、ます。
また、ある単語が本当に未知語かどうかなど、半角・全角などの表記ゆれの違い等への配慮も必要となります。
さらに、AIの分類モデルに着目させる部分を正確に学習させるため、単語の意味表現学習をより正確にしていくことも必要となってきます。前処理は、データ形式を揃えるためだけではなく、どんな文字や単語がよく出現し、置換されたか、何が不要だったかなどの追加情報や、別のタスクでも扱うことのできる単語リストなどの意図しなかった副産物が得られる場合があります。
ご存知の通り、日本語は英語などに比べて文字の種類が多いことが特徴です。
ひらがな・カタカナ・漢字・記号等があります。
さらに、英語などのように単語間にスペースが入らないので、単語分割を行ったうえで、単語の定義が必要になります。
つまり、適切な解析単位の把握と単語の意味についてのエンコードが必要です。
これを行うことにより、モデルをチューニングすることよりも、簡単に結果の制度改善につながるといった場合もあります。
このように、前処理は、後段処理に大きく影響を与えることが重要なポイントであることがお分かりいただけたと思います。
実際に、機械学習などを用いた自然言語処理において、一般的な前処理として、コーパスクリーニング → 単語分割 → ベクトル化(モデル入力前まで)というフローがあります。
今回は「コーパスクリーニング」と「単語分割」に着目します。 -
Pythonを活用した、一般的な前処理の手順
1. 不要な文字列削除
文章から解析に不要な文字列をどんどん除去していく必要があります。
この際、「何が不要な情報であるか」はプロジェクトの趣旨により変わると思いますので、それに合わせて除去する対象を取捨選択していきます。基本的には、正規表現で文字列をヒットさせて、空文字列またはスペースに置換させる方針が一般的ですが、便利なライブラリやメソッドがあった場合は本記事ではそれらを使用しています。
実際、正規表現を用いる場合は、こちらの正規表現確認ツールが大変便利です。改行コードの削除
改行コードには、CR(r)、LF(n)、CR+LF(rn)が種類としてはあるため、下記のように “r” と “n” のどちらも削除する方針を取ります。text = ‘こんにちは!nお元気ですか?n私は元気ですn’
text = text.replace(‘n’,”).replace(‘r’, ”)
# text => ‘こんにちは!お元気ですか?私は元気です’
なお、上記の他には splitlinesメソッドで分割する方法などがあります。
URL削除
こちらは正規表現を用いて削除します。reライブラリを使います。import re
text = re.sub(r’http?://[w/:%#$&?()~.=+-]+’, ”, text)
text = re.sub(r’https?://[w/:%#$&?()~.=+-]+’, ”, text)絵文字の削除
demojiライブラリを使用し絵文字を削除します。import demoji
text = demoji.replace(string=text, repl=”)半角記号削除
こちらはつなげて削除します。半角ハイフン “-” については”Wi-Fi”など単語としてハイフン込みで成り立っているものがあるため、削除対象からははずしてあります。text = re.sub(r”[!”#$%&’\\()*+,-./:;?@[\]^_`{|}~「」〔〕“”〈〉『』【】&*・()$#@。,?!`+¥%]’, ”, text)
全角記号削除
とくにライブラリなどがなかったため、以下のようにして削除します。text = re.sub(“[uFF01-uFF0FuFF1A-uFF20uFF3B-uFF40uFF5B-uFF65u3000-u303F]”, ”, text)
2. ルールに沿った文字列の変換
全角英数字を半角英数字に変換し、1回以上連続する長音記号を1回に変換します。さらに、3. の単語への分割には辞書ファイル「mecab-ipadic-NEologd」で推奨されている正規化処理として「neologdn」ライブラリを使用します。
pipコマンドでインストールしましょう。
> pip install neologdn
neologdn の normalize メソッドは、全角英数字を半角英数字に変換したり、漫画や小説などにある「キャーーーーーー」といった連続した長音記号を削除して「キャー」にする、などの変換をしてくれます。
import neologdn
text = neologdn.normalize(text)桁区切り数字を 0 に変換
12,345,678 のようなコンマ付きの数字は、すべて 0 に変換します。text = re.sub(r’bd{1,3}(,d{3})*b’, ‘0’, text)
数値を全て 0 に変換
数値が重要な意味を持つような後続処理でなければ、すべて 0 に置き換えます。text = re.sub(r’d+’, ‘0’, text)
大文字を小文字に統一
大文字・小文字どちらに寄せるかは状況にもよりますが、いったん表記揺れしないようにどちらかに統一します。
今回は小文字に揃えましょう。text = text.lower()
3. 単語への分割
MeCab + mecab-ipadic-NEologd の導入
英語のようにスペースで単語が区切られていない日本語の場合は、はじめに単語単位に文章を分割する必要があります。
そこで対象の文章を意味のある最小単位に分解し、品詞・意味を割り出す処理を行います。
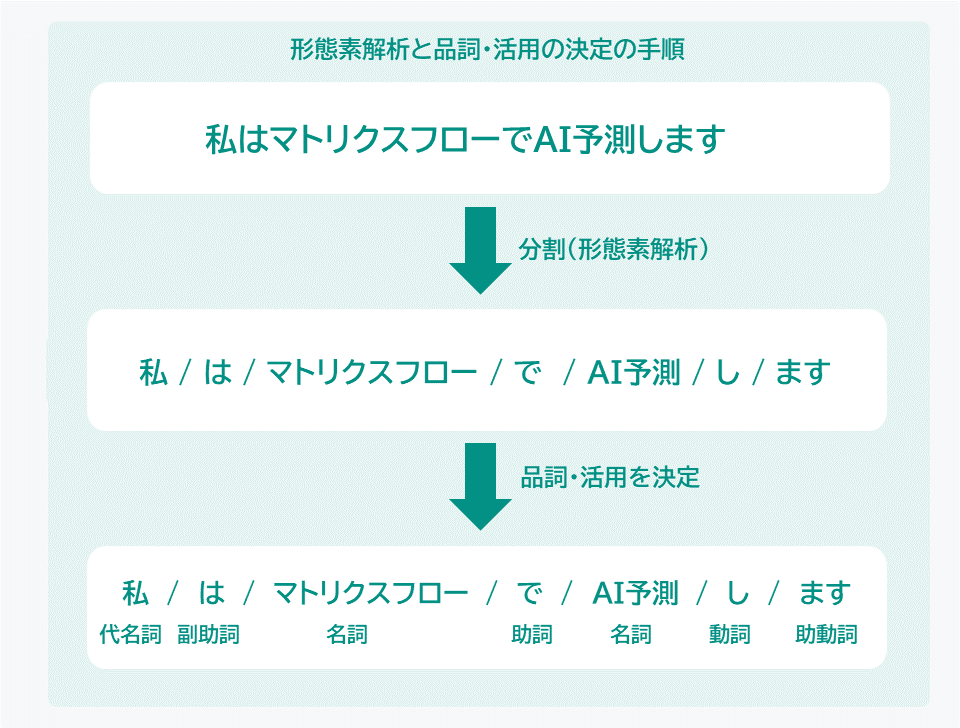
この処理を「形態素解析」といいます。形態素解析とは、私たちが普段生活の中で一般的に使っている言葉、つまり「自然言語」を形態素にまで分割する技術のことです。
形態素とは、「言葉が意味をもつまとまりの単語の最小単位」のことです。
例えば、「私はマトリクスフローでAI予測します」という文章を形態素解析すると「私(代名詞)/は(副助詞)/マトリクスフロー(名詞)/で(助詞)/AI予測(名詞)/し(動詞)/ます(助動詞)」というように言葉を分割していきます。
今回は、形態素解析としてもっともメジャーだと思われる「MeCab」を使います。
MeCabは形態素解析用のエンジンであるため、辞書などはデフォルトのものや、外部の他の辞書を合わせて利用することもできるという点が便利です。pipコマンドでMeCabを導入しましょう。
> pip install mecab-python3
ここでは、 辞書としてmecab-ipadic-NEologdを利用することとします。
「mecab-ipadic-NEologd」は形態素解析エンジン「MeCab」と共に使う単語分かち書き辞書で、週2回以上更新されます。そのため、新語・固有表現に強かったり、語彙数が多かったりする特徴があります。
MeCab にあわせて mecab-ipadic-NEologd の辞書を使うことによる効果として、「マトリクスフロー」など新しい単語などが「マトリクス/フロー」などと分割されずにきちんとひとつの単語として認識されるようになります。mecab-ipadic-NEologd 導入については公式の日本語READMEを参考にしてください。
形態素解析する
import MeCab
# 解析対象の文字列を用意
text = “マトリクスフローとはなんぞや”# 辞書を指定しタガー生成
tagger = MeCab.Tagger(“-Ochasen -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd”)# 形態素解析結果を出力
for line in tagger.parse(text).splitlines():
print(line)
結果は以下の通り出力されます。マトリクスフロー マトリクスフロー マトリクスフロー 名詞-固有名詞-一般
と ト と 助詞-格助詞-引用
は ハ は 助詞-係助詞
なんぞ ナンゾ なんぞ 助詞-副助詞
や ヤ や 助動詞 特殊・ヤ 基本形
EOSタガー生成時に指定している「-Ochasen」はMeCabの解析結果の出力モードの一つです。
指定しない場合はデフォルトの出力になります。
今回、4. の必要な単語の抽出でChaSen品詞体系と呼ばれる品詞体系で絞り込みを行う予定なのでChaSen互換形式である-Ochasenを指定します。4. 必要な単語の抽出
品詞による抽出
文章を単語単位で分割したあと、多くの場合は、すべての単語が必要になるわけではありません。そこで、それぞれの品詞について、必要な単語かどうかの選別を行うステップが必要になります。
ここでChaSen品詞体系として品詞を出力し、品詞体系の表を見ながら、必要になりそうな品詞の種類をリスト化しておきます。
target_parts_of_speech = [
”名詞-サ変接続”,
”名詞-形容動詞語幹”,
”名詞-一般”,
”名詞-固有名詞-一般”,
”名詞-固有名詞-組織”,
”形容詞-自立”
]ストップワードの除去
ここまでのステップで、品詞によっては、抽出した単語の中にどうしても不要な単語が混じってしまうことは避けられません。そこで「ストップワード」と呼ばれる、特定の意味をなさない「一般的すぎる」単語をあらかじめリストとしてもっておきます。これをストップリストと呼びます。
ストップリストにある単語を除外する処理を今回は実施します。
ほかにも、出現頻度などで除外する方式などがありますので、プロジェクトの状況に合わせて使い分けが必要となります。一般的な日本語のストップリストは、例えばSlothLibプロジェクトなどから取得できます。
こちらのストップリストだけでなく、自分が処理したいテキストの専門分野特性などを加味して、除外したい単語を抽出し、自分でストップリストを手作業で作成することが必要な場合もあります。
実際に抽出する
品詞による抽出とストップワードの除去を行った実装例は以下のようになります。
品詞による抽出とストップワードの除去を行った実装例は以下のようになります。
# 処理対象の文章
text = “マトリクスフローとはなにかを知るため我々は社員にインタビューした”# SlothLibプロジェクトから取得したストップリストを読み込む
with open(‘./japanese_stop_words.txt’) as f:
stop_words = f.read().splitlines()result_word_list = []
for line in tagger.parse(text).splitlines():
if line is None or line == ” or line == ‘EOS’ or len(line.split()) < 4:
continue
for target_part_of_speech in target_parts_of_speech:
if target_part_of_speech == line.split()[3]:
word = line.split()[2]
if not word in stop_words:
result_word_list.append(word)print(result_word_list)
# ['マトリクスフロー', '社員', 'インタビュー']
結果が表示されました。
-
プログラミング不要でAI予測モデルが構築できる「MatrixFlow」面倒なデータの前処理も簡単!
MatrixFlowはプログラミング不要のAI構築プラットフォームです。
文章・テキストの分析にも対応しています。
アルゴリズムの開発は、処理単位のブロックをドラッグ&ドロップし、繋ぐことで誰もが簡単に実現可能です。
またデータの管理や作成したアルゴリズムの管理など、AI構築に関わるすべての工程を一元的に管理できるので、担当者が変わった場合などでも、すぐに引き継ぐことができる点でもおすすめです。
この開発スキームは、業種・業界によらないものである上、開発を続けることで開発ノウハウがブロック、およびその組み合わせのテンプレートとしてプラットフォーム上に蓄積されていくため、今後のAI開発においてはさらなる開発の早期化、開発費用の低減が期待されます。
ぜひ、詳細はお問い合わせください。
編集部Pickup記事
-
![]()
Excelを使った在庫管理のやり方、表の作り方、使える関数をご紹介!
企業の活動において、消費者であるユーザーが欲しがる商品を、欲しいタイミングで、欲しい分だけ適切に提供できることが、企業が目指すひとつの理想の形ではないでしょうか。 実際、「適正な在庫水準とは何か?」という問いにパーフェクトに答えるのは難しいとはいえ、ある程度の健全な在庫水準を保ち、欠品を防止に務めるのは、およそ商品を扱う企業にとっては共通の使命ともいえるのでしょう。 適性な在庫水準を保つために必要となるのが在庫管理表です。 実際に、紙での在庫管理をしていることも少なくないと思いますが、扱う商品などのアイテム数が多い場合、紙の在庫管理表では管理しきれなくなる可能性も出てきます。そこで便利でかつ的確な在庫管理を可能にするのが、Excelです。 本記事では、Excelを活用した在庫管理の方法について、在庫管理のやり方、表の作り方、使える関数をまとめてご紹介します!
-
![]()
AI動画生成ツール徹底比較!Sora・Runway・Kling・Pika・Veo、2026年最強はどれ?
Sora 2、Runway Gen-4.5、Kling 2.6、Pika 2.5、Google Veo 3.1など主要AI動画生成ツールを料金・画質・生成時間まで徹底比較。無料プランの有無や商用利用、日本語対応まで、2026年に動画制作を始めるならどのツールを選ぶべきかわかりやすく解説します。
-
![]()
主要生成AIモデルの比較:ChatGPT、Gemini、Claude、Llama 3、Grok
生成AIは、ビジネス、教育、クリエイティブ分野で急速に進化しており、その中でもChatGPT(OpenAI)、Gemini(Google)、Claude(Anthropic)、Llama 3(Meta)、Grok(xAI)の5つのモデルは注目されています。本記事では、これらのモデルを以下のポイントで比較します。
-
![]()
AI × Excel活用術!Copilot・ChatGPT・Gemini、エクセル業務を劇的に効率化する方法
Excel × AIの最新活用術を徹底解説。COPILOT関数・Agent Mode・ChatGPT for Excel・Gemini in Sheetsなど、エクセル業務を自動化する3つの方法を、料金・機能比較から具体的な活用例まで紹介します。
-
![]()
NotebookLM活用術|海外で話題の使い方10選と日本では知られていない裏ワザ【2026年最新】
NotebookLMを「音声要約ツール」としてしか使っていませんか? 実は海外では、法律文書の横断分析、AIポッドキャスト制作、競合インテリジェンス、大学の論文レビューなど、日本ではまだ知られていない驚きの活用法が広がっています。2026年3月にはCinematic Video Overviewsも登場。この記事では、英語圏の最新事例・パワーユーザーの裏ワザ・知っておくべき落とし穴まで、日本語記事では読めない情報を徹底解説します。
-
![]()
【業界別】AI・人工知能の活用事例20選!ビジネスにおけるAIの今後は?
近年、AI(人工知能)は様々な分野で活用が進んでいます。 AIを組み込んだ便利な仕組みやサービスが次々に登場し、あらゆる業界で活用され始めています。 この記事では、AIがどのように我々の生活や仕事を便利にするのか、業界・産業別にAI活用事例を解説していきます。






関連した事例
-
![]()
予測分析ツールおすすめ7選比較!AIで予測できること・無料ツールはある?
将来の売上や株価を予測することができれば、ビジネスや投資において非常に有利に動けます。しかし、人の勘や経験に頼った予測には限界があり、正確な予測をすることは困難です。 そこで、あらゆる業界で「予測分析ツール」が注目されています。予測分析ツールを使えば、膨大なデータを分析し、過去の傾向をもとに未来を予測できます。さらに、機械学習や人工知能を使った予測分析ツールを活用すれば、誤差を減らしてより高い精度で予測を行うことができます。 本記事では、予測分析ツールでどんなことが予測できるのか、おすすめの予測分析ツールをご紹介します。AIやツールを使った予測に興味がある方は、ぜひ参考にしてみてください。
-
![]()
AI開発外注の費用相場・期間は?おすすめ開発会社を解説
AIを開発したいと思った時にまずぶつかる壁は、「自社内で開発するか外注するか」です。 社内に開発人材がいる場合もいない場合も、AI開発の外注は選択肢の1つとして考えられます。 AI開発の外注にはメリット・デメリットがあるため、AI開発において重視する内容によって外注が最適かどうか変わってきます。 本記事では、AI開発を外注しようか検討している方に向けて、AI開発の外注にかかるコストやメリット・デメリットを解説します。さらに、AI開発に強いおすすめの外注先もご紹介するので、開発会社選びの参考にしてみてください。
-
![]()
ノーコードでAIを開発する方法とは?開発事例・無料の開発プラットフォームを紹介
ここ数年、国内外の開発者の間で「ノーコード(NoCode)」という言葉がよく聞かれます。 ノーコードとは、文字通りコードいらずでWebサイトやWebサービスを開発する手法のことです。 このノーコードの開発手法を使って、AI(人工知能)を開発しようとする動きが出てきています。 本記事では、ノーコードでAIを開発して自社課題を解決したい方に向けて、ノーコードでどんなことができるのかを解説していきます。 ノーコードを使ってAIを開発した事例も紹介しているので、ぜひ参考にしてみてください。
-
![]()
プログラミングでAIを開発する方法!必須のプログラミング言語・入門知識を解説
近年急速に進化しているAI(人工知能)。 AIを活用すれば、今まで大量の人と時間を投下していた業務も効率よく精度高く遂行できます。 人と同じような動きができるためすごい存在に思えるAIですが、プログラミングを学べば初心者でも開発が可能です。 本記事では、プログラミングをしてAIを開発する方法やAI開発におすすめのプログラミング言語をご紹介します。
-
![]()
機械学習(ML)とは? メリット・種類・業界や課題別の活用例・実施方法を解説
機械学習(Machine Learning)とは、コンピューター(Machine)が与えられた大量のデータを処理・分析することでルールやパターンを発見する技術・手法のことです。学習の結果明らかになったルール・パターンを現状に当てはめることで、精度の高い将来予測が可能となります。 高度なコンピューターを使用することで、人間の脳では処理しきれない複雑な要素を加味した分析・学習が可能となりました。その結果、近年ではさまざまな領域において人間による作業の精度向上・効率化に役立てられています。自動運転や医療、人間の購買行動の分析など、さまざまなビジネス領域で機械学習が実用化されており、今後のマーケットで生き残っていくためには必須の技術になりつつあるといえるでしょう。 本記事では、機械学習(ML)の概要やメリット、種類に加え、業種別・課題別の活用例を紹介します。実際に取り入れる際の作業フローも紹介しているので、機械学習の活用に興味がある方はぜひ参考にしてみてください。
-
![]()
AIやExcelを活用したコールセンターの入電数予測の方法
コールセンターにおけるコール予測(呼量予測、forecaster)とは、お客様からの問い合わせなどセンターで受信する電話の量を予測することをいいます。 コールセンターの運用コストを増加させる要因のうち大きなものが、コミュニケーターの人件費です。コミュニケーターは顧客からの入電に応じてオペレーションの対応をするため、実際の入電数よりも多くのコミュニケーターを配置すると、対応がなく待ち状態のコミュニケーターが増えて、不要な人件費の増加に繋がります。また、逆に配置人数が少ないと呼び出し中でつながらないなどのクレームの要因になりかねません。適正な人員をコンタクトセンターに配置することで、十分な顧客満足度が提供できる状態でオペレーションを行っていることが理想です。今回は、Excelを活用したコール予測、AI(人工知能)による機械学習を用いた時系列分析で、コール予測を実現する方法をご紹介します。
-
![]()
予測分析とは?活用事例とその手法・ツールをご紹介
予測分析とは、過去の行動パターンを特定し、将来の結果を予測するために、大量のデータに数理モデルを適用する手法です。 機械学習、データマイニング、統計アルゴリズムなどの複数の組み合わせがもたらす「予測的手法」により、予測分析ツールは、単純な相関付け以上の機能を実装できます。ビジネス分野では、予測分析が以下に示すようなさまざまな用途に利活用されています。 ・需要と供給のより正確な予測コンピューターネットワークに悪影響を及ぼす脅威と潜在的問題の特定 ・保険サービスや金融サービスにおけるセキュリティリスクの低減 ・クレジットカード詐欺のリアルタイム検出 予測分析機能を組み込んだソフトウェアが増えつつあり、これはあらゆる規模の組織体でユーザーにとって身近なものになっています。予測分析はデータサイエンスや高度な分析に関する訓練を受けていないエンドユーザーにも実務上の価値をもたらします。これは、まさにすべてのユーザーが恩恵を受ける機会を提供することに値します。この概念を「データの民主化」と呼びます。誰もがデータを利用してより良い意思決定を下せるように、組織全体でデータを誰もが利用できるようにするという概念です。 本記事では、予測分析がなぜ重要なのか、予測分析の実活用例、予測分析の手法、機械学習やデータマイニングなどの他のテクノロジーとの関係、モデルの役割、予測分析を始めるにあたってのヒントについてご紹介します。
-
![]()
ディープラーニング(深層学習)とは?概要や、業界・課題別の活用例・導入手法を解説
AI(人工知能)という言葉は昔からありましたが、近年いよいよ本格的に生活のなかで活用されるようになってきました。そのなかで重要な役割を果たしているのがディープラーニング(深層学習)です。従来は機械に任せるのが難しかったケースにも対応できるようになり、さまざまな形で日常生活やビジネスに変革をもたらしています。 しかし、ディープラーニングがどのような仕組みなのか、具体的に理解している方は少ないでしょう。本記事では、ディープラーニング(深層学習)の仕組みや、AI・機械学習との違い、さらに業種別のビジネスへの活用例を紹介します。 ディープラーニングを事業活動に活かしたいとお考えの経営者・事業担当者の方は、ぜひ参考にしてみてください。
-
![]()
製造業におけるAI活用事例23選!各社の導入方法・例をご紹介
ここ数年でAi技術は格段に進化を遂げています。様々な領域でAIの活用が進んでいますが、製造業ではどのくらいAIの導入が進んでいるのでしょうか。製造現場での実用化にはいまだ課題も残っています。AIを活用できる人材がいない、AIの導入方法がわからず、活用が進んでいない企業も多いのではないでしょうか。 この記事では、実際にその仕組みや導入のメリット、成功・失敗事例を紹介していきます。製造業でAIを導入するうえでの注意点についても解説していますので、ぜひ参考にしてください。








